The Semantic Web is the Database:
Decentralised Modeling with
central Coordination
Frauke Weichhardt
Beratung
im Netz
fweichhardt@fweichhardt.de
Christian Fillies
Semtation GmbH
cfillies@semtalk.com
Bob Smith
Cal. State University,
USA
robsmith5@1talltrees.com
Abstract
Knowledge Management has become a widely accepted
discipline in corporate functions and people have gained some experience in
introducing and conducting these systems. From
these experiences the introduction of KM systems consists of at least two
steps:
First, developing an ontology
strategy; second using this strategy to design and develop an ontology for knowledge management, including document classification.
Fundamental to any kind of KM system is
developing a common language and understanding of the domain. This usually
results in an ontology and in most cases to business process models describing the relevant domains.
As the process of developing process and
ontology models is rather time consuming you want to use them for quite a long
time. This means you need to maintain them. This is the point where many systems fail. Traditionally maintenance is done in a
centralized way. Therefore the models are never up to date. This article
proposes a different approach: decentralized modeling with central
coordination. We describe this methodology and a tool based on Semantic Web technology [1] that is able to
support this new way of ontology development and process modeling.
1. From enterprise
models to corporate Semantic Webs
·
Define Enterprise Models, describe the role of enterprise models in corporate semantic Webs
·
Users interfaces for
building and using a corporate semantic Web
Enterprise models became popular in the
Eighties. They are a reasonable starting
point for a corporate semantic web as they provide the
logic for an organizational structure, expose the most
important business processes, and describe requirements and blueprint of the firm’s
information needs. They are used for various
purposes starting from the implementation of ERP software systems to quality
management systems. In some situations even business process reengineering is
still an issue if you are considering mergers and acquisitions. People became
quite familiar with models so that it is not
really a big step to generalize them in order to visualize and
create a corporate wide semantic web of knowledge, though no successful Corporate Semantic Web yet exists.
Humans seem to be able to capture complex scenarios faster by graphical
pictures. Graphical notations have been playing a major role for business
process modeling, data modeling and describing software systems with UML. Most graphical models have been build on a department level using drawing tools like Visio or ABC flow charter. We are combining now both
sides by providing a graphical modeling tool for semantic webs on top of Visio. Visio allows us to use a virtually
unlimited set of pictograms and symbols to make the model understandable for
end users. The notations have to match the technical level of the intended
reader and should therefore be less technical as for example UML. [6]
In the context of Knowledge Management, Yellow Page systems are quite popular for global and
distributed companies. Corporate yellow pages are enterprise models in that sense that they form a
directory of employees often reflecting the organizational or regional structure of the
corporation. In some rare case you will find business process oriented entry
points to a yellow page
system.
Yellow Page systems make up a kind of database in
which managers can express their needs
for personnel, and employees present their skills and experiences. But
current systems often allow just the selection of a couple of features from a
given list of skills. The most advanced systems allow several classifications of skills.
A typical example in a software company might
be programming languages. Consider a case where you may be able so select from Fortran, C++, Java, UML and from consulting skills as
interview techniques and BPR tools. Every project manager can easily find experts in his
worldwide distributed organization with those systems.
Once a new project is going to start using C# and DotNet-Web Services the project manager is going to have a problem finding
people, since the skill taxonomy does not match any of the required skills,
because his company never did a DotNet project before. He is going to reject the project or hire expensive
external consultants.
Semantic Web technology can help to solve many
of the issues mentioned above and therefore helps to save a lot of money to the
company. Using a more detailed semantic network we can define synonyms and homonyms for the terms. E.g.
what is a “process” from the point of view of web services? What is the
similarity between a web service and a component in classical style UML software modeling? C#
is not a synonym of Java. It is just closer to Java than to C++ and much closer than Fortran.
We have explained this concept of weighting relationships in more detail in
[3].
With a more sophisticated graphical semantic
knowledge base the project manager, who usually just wants to solve his application problem, has a much better chance
to learn that he needs business process experts to specify the functional
behavior of web services rather than programmers. If the system is good, he
gets an impression how far away DAML-S is from existing process modeling
approaches.
We have to stress the point that this can be
done just by adding meta data on a conceptual level.
This does not require every employee to frequently change
his skill description.
2. Centralized vs. Decentralized Ontologies
·
What kind of ontologies can be useful
for such corporate semantic Webs
No company is going to build “the” monolithic corporate ontology. Ontologies used for Knowledge Management in a corporation must be capable of
reflecting the different interests, usage scenarios and rapid changes existing in a
social system. But they have to ensure the key idea of the Semantic Web: If people have identified that
they are talking about the same topic, this denotable thing should have a unique way
to be referenced in models. But pragmatic approaches have to allow for contradictions, different
importance weight of information and often subtle cultural
differences.
The usual way of creating an
ontology is to ask someone specialized in modeling to find out what is
needed. This person then might talk to some employees of the company and build the
model. This will cost a high amount of money, as specialists usually are
expensive people. On top, an ontology created by someone that is not really inside
of business processes, usually suffers from acceptance problems, as a lot of
people will not understand it.
Furthermore you have to reflect the need of maintaining models, as models that
are not up to date, cannot be used anymore. If there is a central ontology
model that can only be taken care of by a few specialists, the probability that
the model will be up to date is very low.
Instead those people, who create or experience
changes, should create and maintain models. For these people you usually have a problem, motivating them to
update their models, as modeling is something on top of their “real” work. This
means modeling must be made extremely easy and add a personal benefit to their daily work.
Additionally personal goals have to reflect the efforts
spent on knowledge
management.
2.1 Sample Projects
·
Concrete applications of corporate semantic Webs
Projects in this area usually are focused
on a specific application domain. Typical projects are ontologies for an IT department in order to maintain a consistent
vocabulary within their own documentation and for classification of external documentation
[4].
Another use case is Systems Management where a classification and semantic net of
technical infrastructure makes a lot of sense. In this case visualization e.g.
using Visio diagrams is very popular. Ontologies of the shapes used
and possible relationships are very helpful
to ensure consistency and reusability of those drawings. Adding an ontology layer helps at navigation and offers a
kind of knowledge base covering types of resources involved in those drawings.
The third use case we want to mention is CRM.
For creating an intelligent CRM systems the basic steps are:
1. Classification of customers;
2. Classification of services or outputs;
3. Mapping of customer class to business process modules.
If CRM has to be applied in a global context but must also remain sensitive to numerous local variants it has to be organized
by a common ontology in order to ensure the consistency of the offered
services. This consistency is needed for basically two reasons:
More efficient internal business processes and on the other hand to be
recognizable as a company in classical markets such as US and Europe but also in
the new emerging markets as eastern Europe and China.
2.2. Local Inconsistencies / Different Viewpoints
·
Cooperative building,
adaptation and evolution of a corporate semantic Web
·
Agent-based approaches for building and
management of a corporate semantic Web and for information retrieval from a corporate semantic Web
·
How to tackle multiple
viewpoints in a corporate semantic Web
We do not assume one
consistent ontology for a company like IBM or even Microsoft ever to be
built. Our approach is to create something like
“Islands of Consistency”. Those islands may be connected to each other by
bridges (or hyperlinks).
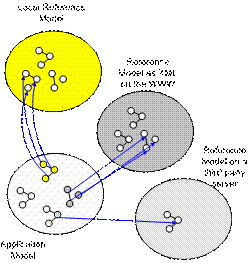
Fig.1. Distributed
and hyperlinked models
The local or “decentralized” models should
refer to common or “centralized” ontologies wherever possible as shown in
Fig.1. Models can be replicated using the included hyperlinks. This technique
is used to ensure consistency in case the referenced models
has been changed. The set of models has to be ordered by the frequency
of changes. The most general models containing the basic classes like “Customer” or “Order” are
assumed to change with a very low frequency. Models on department level may change more frequently.
Models on a project or in the extreme case on document
level are a subject of frequent changes. The references have to be organized in
a way that the “working models” always link to “reference models” which are
characterized by a higher degree of stability.
Technically this is not much more than using namespaces in XML and publishing schema
information on well defined locations on the internet. But applying this concept to
modeling for the purpose of Knowledge Management is basically an organizational task.
Ensuring this consistency requires tool support while modeling e.g. using
an agent-based approach looking for
similarities in the models. We have added to the modeling tool SemTalk [2] an agent which helps to lookup names used in the
current model. Once this agent finds
the object name in a reference model, it can convert this object into a hyperlink to the other model.
But even if modeling is supported by an agent-based infrastructure, an organizational process for model reviews and quality control done by human experts will be needed.
Ontologies for a corporation can not be
elaborated and maintained by one centralized team. Users on department level have to be empowered to build
their own ontologies and model, referencing and sub-classing general models or Visio Templates provided by
the central team.
From this assumption the requirements for the
authoring tools can easily be found: embedded into
desktop applications, short learning curve and
primitive graphical notations.
Fig.2. visualizes that ontologies are being
used in very different scenarios.
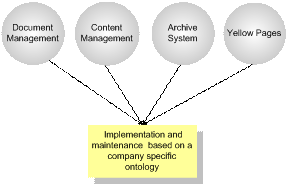
Fig.2. Usage Scenarios for Ontologies
All these document oriented solutions need an
ontology or taxonomy to classify
the content. All their users have to be able to add meta
data to documents during annotation. If we really want to
describe the content of the document the users have to be able to extend the ontology. They have to be able to contribute to the corporate Semantic Web.
Another application we have built is
an “Ontology Checker” comparable to the spell-checker
for Microsoft Office
XP using SmartTag technology. The Ontology Checker
parses the text while it is entered.
The Ontology Checker gives the user access
to the ontology to help him understand whether he is using a word correctly.
Since distributed, decentralized ontologies are
implementing a system of different viewpoints the tools using the ontologies must be aware
of local models. E.g. for the “Ontology Checker” you can specify which
ontologies (application domains) are relevant for you in
the current Office document.
3. Strategies to build Ontologies
·
How to build such
ontologies
There are obviously numerous ways how to start
building an ontology. In order to make this process as
efficient as possible we are using three different approaches:
o Internal information found in business processes
o External Outputs and products of an organization
o Analysis of selected documents
The first two strategies are related to
business processes. The difference between these two approaches is the origin
of the objects. In the first case we are analysing the process steps and information flows within a
process. In the second case we are starting from the information flows between
different business partners or their major processes. This has been used in the
CRM project mentioned above.
3.1 Ontologies and Processes
·
Management of multilinguism in a corporate semantic Web.
Using business process models for creating
ontologies is not a very common procedure yet, as it is not supported by many tools, but it does have
some advantages:
-
A lot of knowledge is
very often procedural knowledge which has to be captured anyway;
-
Using processes with
information flow helps to control the modeling depth. One of the major risks
while building ontologies is to get lost in details. Using processes helps to
focus on the most important business objects;
-
Process models in many
companies already exist. Those (legacy) process models can be analyzed. The
business objects and methods are being extracted from function
or activity names. “Reengineering” of process
models is very often needed to be able to consolidate multiple models resulting
from recent projects or in cases when process models
have to be translated to different languages. Both problems will be eliminated
once process models are being built on top of existing ontologies.

Fig.3. Creating Ontologies from
Business Processes
The main idea of ontology based process
modeling is to compose function (activity) names from object names and verbs found in an ontology. As shown in Fig.3. this
is an iterative process which can start from ontologies, from process or even
from published ontologies.
You may even begin with a blank ontology and build the business objects step by step from the process.
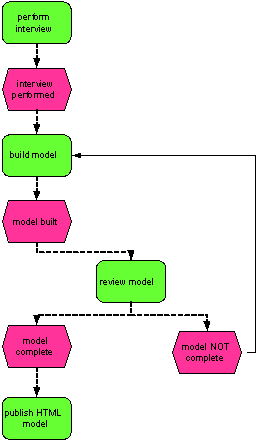
Fig.4. a sample object oriented process
From the sample process in Fig.4 “Interview”, “ Model” and “HTML-Model” can be recognized as important objects for a taxonomy of the problem
domain. We can even describe operations such as “publish” in the ontology. “HTML Model” should become a subclass of “Model”.
Once the process models are created in this strongly
formalized way with a minimum number of verbs and well defined objects, they can be easily
translated to different languages.
3.2 Ontologies built from Text
Documents
We are trying to collect data for building
ontologies from all available corporate information sources, but for a given project in most of the cases textual documentation has to be reviewed
and at least partially modeled. This applies if a whole set of documentation
has to be modeled or even if just one document is going
to be annotated.
For building ontologies from text documents we
have been using a semi-automatic methodology. We have been using TextTech’s Concept Composer [5] to extract domain terminology
and collocation using a statistical comparison on sentence level.
The main goals of an ontology project are the definition of the most
important keywords in order to minimize communication problems, foundation for
a Knowledge or Content Management System with model-based access to documents and from Semantic Web point of view most important:
simplified review and annotation of existing and new documents.
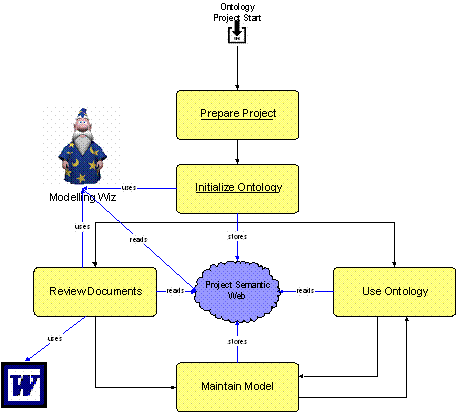
Fig.5. a methodology for setting up ontologies
Creating an initial ontology is a quite simple
process:
1. Start from a list of e.g. 250
manually selected most important terms
2. Extract domain specific technical terms
and collocations
3. Define 200 terms in 7 one-day workshops with participants from several departments.
4. Create models
5. Broadcast the model on the intranet
The Project Results from this initial project are:
§
Visual Glossary
§
A Model of classes in several graphical scenarios
§
Model can be exported
to other applications
3.3
Maintaining the model
·
Modeling expertise conflicts
While the model is published on the intranet,
users will notice wrong or missing concepts. They then are supposed to
customize the general model to their specific needs. They build their local
model by basically reusing existing classes or introduction of new classes and properties. New classes are automatically compared with
the central model by the consistency wizard.
Regularly a model supervisor creates reports on existing classes, finding concepts that seem to be
in conflict. He then decides if this conflict is important enough to be
discussed centrally. If it is, he starts and controls the discussion.
Participants of the discussion should be modelers or their representatives from
each involved department. If the conflict cannot be solved,
both concepts remain in the model, being marked with their specific namespace. Very often namespaces are created according to organizational units. In this way the model
supervisor also takes into regard that the ontology might be used for several applications and makes sure that it applies to
all requirements those applications might have. His responsibility is also to compare new concepts to
externally provided ontologies in order to ensure that external concepts are
used in the way the company needs it (e.g. eCl@ss.de
(www.eclass.de) or unspsc
(http://eccma.org/unspsc/)).
The result of organizing your modeling
activities in this way is a network of models, referencing each other and based
on some central concepts. It grows by time and develops towards a comprehensive
collection of concepts used in the company, which someday could be called a
language.
4.
Summary and future work
No Corporate Semantic Web yet exists. The vision and the high level of funding over
the last two years has yielded the conceptual and
technical foundation for extensive business to business transactions.
This paper has described both tools and technologies for building upon
available resources wisely. Without flexibility and extensibility,
expensive systems can be built but only to fail in practical use. By designing
a flexible strategy for the creation of ontologies that is centrally
coordinated and locally modeled future ontology projects, e.g. EAI projects, can be realized much easier at
much lower cost.
5.
References
|
[1]
|
Tim Berners-Lee, Jim Hendler, and Ora Lassila published an article about
the Semantic Web in Scientifc American. "A new form
of Web content that is meaningful to computers will unleash a revolution of
new possibilities". http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
|
|
[2]
|
Fillies,C.; Weichhardt, F.; SemTalk: A RDFS Editor for Visio 2000
Position Paper, ICCS 2001 9th International Conference on Conceptual
Structures / Semantic Web Working Symposium (SWWS)
|
|
[3]
|
Hong-Gee Kim, Christian Fillies, Bob Smith and Dietmar Wikarski: Visualizing a
dynamic knowledge map using Semantic Web technology,
EDCIS2002 (submitted)
|
|
[4]
|
Fillies, C., Wood-Albrecht, G., Weichhardt, F., A Pragmatic Application of the Semantic Web Using SemTalk. WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA ACM
1-5811-449-5/02/0005
|
|
[5]
|
Heyer, G.; Läuter,
M.;Quasthoff, U.; Wittig, Th.; Wolff, Chr.: Learning Relations using Collocations. In: A. Maedche, S. Staab, C. Nedellec and E. Hovy,
(eds.). , Proc. IJCAI Workshop on Ontology Learning, Seattle/ WA, 19. - 24. August 2001
|
|
[6]
|
Fillies, C.; Sure,Y: On Visualizing the Semantic Web in MS Office, 6th
International Conference INFORMATION VISUALISATION, LONDON · ENGLAND
|