Das semantische Unternehmensprozessweb; Aufgaben- und rollengerechte Informationsversorgung durch vorgebaute Informationsräume[1]
Antonius van Hoof
Christian Fillies
Abstract: Zielsetzung im Projekt PREBIS (PRE-Built Information Space) ist es, die in unterschiedlichsten Formaten vorliegenden Informationen eines Unternehmens in Form eines Informationsraums mit rollenspezifischen und aufgabenbezogenen lernfähigen „Wegweisern“ seinen Mitarbeitern zugänglich zu machen. Die Informationen stammen aus unterschiedlichsten internen und externen Quellen. Aus Geschäftsprozessbeschreibungen, Organisations- und Qualitätssicherungshandbüchern, Produktdatenmodellen und sonstigen Dokumenten werden inhalts- und kontextbezogene Ontologien gewonnen, die mittels Semantic Web-Technologien modelliert und mit Verfahren des Information Retrievals so verknüpft werden, dass Informationssuche und -präsentation effektiver und effizienter ausgeführt werden können.
Kontextualität des Informationsbedarfs
Wie überall ist auch in Unternehmen die Informationsversorgung ihrer Mitarbeiter durch „Unterversorgung wegen Überhäufung“ gekennzeichnet .Der Bestand an Informationen, derer sich Unternehmen bedienen können, ist so groß und unübersichtlich, dass er im Rahmen von Aufgaben der Mitarbeiter kaum sinnvoll nutzbar erscheint. Dies gilt insbesondere für schwach strukturierte wissensintensive Geschäftsprozesse an denen unterschiedliche Akteure beteiligt sind, zum Beispiel bei der Erschließung neuer Marktsegmente, Projektmanagement, Entwicklungsaufgaben oder dem Service von Investitionsgütern (vgl. [ALS02], [FG02], [KW00]). Diese Problematik lässt sich nicht mit einfachen, meist eindimensionalen, Klassifikations- und Indexierungskonzepten fassen. Komplexere Ansätze scheitern zumeist an dem damit verbundenen Klassifizierungs- bzw. Indexierungsaufwand. Viele Informationsquellen wie Fachdatenbanken oder Lieferanteninformationen, sowie externe Internetsites werden nicht direkt durch das Unternehmen gepflegt, und sind damit nicht unter seiner Kontrolle (vgl. [FG02]). Als bestmögliche Lösung hat sich hier zur Zeit die Volltextrecherche etabliert, deren Problematik (Formulierung der Suchanfrage, zu viele irrelevante Treffer, usw.) zur Genüge bekannt ist. Insbesondere die Volltextrecherche wirft den Benutzer auf sich selbst zurück; Bei der Entwicklung von Suchstrategien und Anfrageformulierungen ist er auf sich gestellt. Die Bewertung der Resultate bleibt bei ihm. So können Kollegen voneinander nicht explizit (dokumentiert) von Erfahrungen und ermittelten Informationen profitieren.
Im Unternehmen arbeitet jedoch der einzelne nicht für sich allein. Er ist eingebettet in eine Aufbauorganisation und arbeitet an Aufgaben innerhalb von Geschäftsprozessen, die gestellt wurden um Unternehmensziele zu erreichen. Beides zusammen definiert einen Kontext, der bei der Informationssuche und -versorgung zu berücksichtigen ist (vgl. [KB02], sowie auch [De02], [Ja02], [NTB01). Hieraus lassen sich Elemente für eine kontextabhängige Strukturierung der vorliegenden und neu zu erstellenden Informationen in einem Unternehmen ableiten.
Projektzielsetzung PREBIS
PREBIS unterstützt die geschäftsprozess-integrierte Informationsversorgung in Fachabteilungen von Unternehmen. Ausgehend von Dokumenten und Anfragen wird eine semantische Beschreibung entwickelt, die ein aufgaben- und rollengerechtes Auffinden von Informationen verbessert. PREBIS bezieht sich auf digital verfügbares Wissen aus verschiedenen, auch unstrukturierten Quellen wie Mail- oder Fileservern. Informationsmenge und Detaillierungsgrad der Ergebnisse sind einstellbar. Durch eine ontologiebasierte Indexierung der Informationen und einer automatischen Vorauswahl einiger Quellen und Dokumente wird der spezifische Informationsbedarf eines Benutzers für seine Rolle und Aufgabe erfüllt. Suchstrategien lassen sich auf der Ebene von Personen oder Rollen speichern, PREBIS lernt durch Tracking- und Recommender-Funktionen.
PREBIS liefert neben der Software eine pragmatische Methode zur Herleitung und Verwendung unternehmensspezifischer Ontologien für den Betrieb. Der spezielle Nutzen von PREBIS liegt im schnellen und standardisierten Zugriff auf die gesuchten Informationen. Je größer die Ähnlichkeiten zwischen Unternehmen hinsichtlich der drei Kategorien Geschäftsprozesse, Begrifflichkeiten und Rollenverteilungen sind, desto einfacher lassen sich generische branchenweite Lösungen individuell adaptieren.
Die Innovation in PREBIS besteht nicht so sehr in der Verwendung von Ontologien für Informationsversorgung, sondern in die weitgehend automatisierte Gewinnung und Kontextualisierung dieser Ontologien, sowie in die Verbindung bzw. Kombination von Methoden, Werkzeuge und Anwendungen zu Prozessmodellierung, Dokumentenanalyse und -Clustering, Information Retrieval und Community-Building.
Als praktisches Projektergebnis wird angestrebt, dass ein Benutzer in Abhängigkeit von seiner Rolle und seinen damit verbundenen Aufgaben im Unternehmen einen Informationsraum (Dokumente/Informationen strukturiert und klassifiziert nach Elementen der für ihn relevante Teilontologie) präsentiert bekommt, der genau auf seinen Bedarf abgestimmt ist. So hat ein Entwickler einen anderen Bedarf hinsichtlich Informationsart, -tiefe und -umfang als beispielsweise ein Vertriebsmitarbeiter. Darüber hinaus berücksichtigt PREBIS die Berührungs- und Überschneidungspunkte solcher Informationsräume. Dabei kann der Marketingleiter z.B. jederzeit auf die aktuellen Marktanalysen der Produktmanager zurückgreifen. Auch können unterschiedlichste Vorgehensweisen wie Patentrecherchen oder Einkauf mit den dazugehörigen externen Datenquellen als Gruppenintelligenz abgespeichert und gemeinsam genutzt werden. Ein Entwickler, der im Rahmen seiner Arbeit vielleicht nur selten einen Lieferanten für eine bestimmte Aufgabe sucht, kann somit beispielsweise den Geschäftsprozess (d.h. den strukturierten Zugang zu relevanten Informationen) eines professionellen Einkäufers für sich nutzen. Erprobt soll der Ansatz werden bei Firmen der Maschinenbau-, Automobilzuliefer- und IuK-Industrie, wie auch in einer öffentlichen Verwaltung.
Geschäftsprozessmodellierung, Dokumentenanalyse und Ontologien
PREBIS befasst sich mit Verfahren, die pragmatische, bereichsspezifische Ontologien aus vorhandenen Prozess-Modellen und Dokumenten herleiten. Dazu werden Geschäftsprozessmodelle importiert bzw. direkt graphisch modelliert mit SemTalk, eine Anwendung entwickelt von der Firma Semtation, die auf das Microsoft Graphikprogramm VISIO aufsetzt (vgl. [FWW02]). SemTalk ist ein Metamodellierungswerkzeug in dem beliebige Metamodelle zur Modellierung hinterlegt werden können. Für das hier beschriebene Prozessmodellierungsproblem wird die Methode KSA (vgl. [KF89]) gewählt. SemTalk ermöglicht einen objektorientierten Ansatz, indem Aufgaben bzw. Funktionen in Prozessen als Kombinationen von Objekten und deren Methoden dargestellt werden können. Das Tool stellt die Konsistenz der Funktionsnamen sicher. Beispielsweise beziehen sich im Bereich der öffentlichen Verwaltung die Aufgaben „Flächennutzungsplan ändern“ und „Flächennutzungsplan einsehen“ jeweils auf dasselbe Objekt „Flächennutzungsplan“. Wird das Objekt "Flächennutzungsplan" umbenannt, dann wird es in allen zugehörigen Funktionen und deren Verwendungen aktualisiert. Man kann die Objektnamen und ihre Verben entweder während der Modellierung („Bottom-up“) anlegen oder auf bestehende Bibliotheken zugreifen („Top-Down“). Wichtig ist auch, dass die Verben (oder „Methoden“) zwischen den Objekten vererbt werden. Definiert man z.B., dass man einen „Plan einsehen“ kann und dass ein „Plan“ ein „Bebauungsplan“ ist, erbt der „Bebauungsplan“ das Verb „einsehen“ vom „Plan“. Auch hier hilft die Objekt-Orientierung mit ihrer Vererbung bei der Verbesserung der Qualität der Modelle, da die Begriffe in sich konsistenter und auf den richtigen Abstraktionsebenen benutzt werden.
Dass man einen „Plan ändern“ und einen „Plan einsehen“ kann, ist offensichtlich mindestens abteilungs- und prozessübergreifend gültig. Der Flächennutzungsplan spielt dagegen nur in einigen spezifischen Prozessen eine Rolle. Das Wissen, was ein Plan ist und was man damit tun kann, ist eher statisch: Es ändert sich praktisch nicht. Der Begriff Flächennutzungsplan kann sich hingegen etwas häufiger ändern, wenn auch nicht so oft wie die Geschäftsprozesse, die damit zu tun haben. Die Konsequenz aus dieser Betrachtung ist, dass SemTalk die Modelle in einzelne Teilmodelle gliedert. Die Teilmodelle können an physikalisch unterschiedlichen Stellen abgelegt und von unterschiedlichen Personen gepflegt werden. Ein solches (Teil-) Modell enthält eine Menge von Objekten mit einem ähnlichen Abstraktionsgrad, gegliedert in sachlogische Szenarien oder Kontexte. Durch Teilmodelle und die Verwendung von Namensräumen können mehrfache Bedeutungen des gleichen Wortes repräsentiert und kommuniziert werden. Die Benutzung von physikalisch separierten Teilmodellen ermöglicht ebenso die verteilte Modellierung; Mehrere Personen, bzw. Organisationseinheiten können getrennt von einander ein komplettes Modell bauen.
Am wichtigsten für eine Unternehmensontologie ist die Verarbeitung der im Unternehmen geläufigen Begriffe und deren Bezug zu breiteren Kreisen (Branche, Wissenschaft, Land, Welt). Technische Hilfsmittel zur Extraktion von Fachbegriffen sind dabei spezielle Datenbanken oder Text-Mining-Verfahren. Im Rahmen von PREBIS wird das linguistisch-statistische Textanalysewerkzeug ConceptComposer der Firma text:tech eingesetzt. Mit diesem Werkzeug lassen sich aus unternehmensinternen Dokumenten wichtige Kernbegriffe und einige semantische Beziehungen dieser Begriffe zueinander identifizieren (Statistische Kollokationsanalyse, vgl. [HL2001]). Über eine Schnittstelle zu SemTalk können diese direkt in die Prozessmodelle und Ontologien eingebaut werden.
Das Resultat der Modellierung (Prozess-, Organisations-, Funktions-, Informations- und Ressourcenmodelle) wird in der Semantic Web Sprache OWL (vgl. [OWL02]) abgelegt und steht dann als Bibliothek zur Verfügung. Speziell zur Verwendung in Prozessmodellen können auch schon Verben und Attribute, soweit vorhanden, mit erfasst werden. Oft lassen sich an dieser Stelle auch externe Glossare einbinden. Gerne genutzt werden zum Beispiel die Business Objekte aus dem SAP R/3 ASAP Toolkit. Es stehen aber auch andere Begriffssysteme zum Teil sogar als WebServices (in OWL) zur Verfügung (vgl. [Br01], [CCM01], [GM02]).
Benutzung der Ontologien in PREBIS
Die Leitgedanke des Semantic Web, dass die Verständigung zwischen Mensch und Computer sowie zwischen Computern verbessert bzw. automatisiert werden soll (vgl. [BHL01] wird in PREBIS nicht in erster Linie für das Web aufgenommen, sondern für den Umgang mit vorhandenen Informationen in einem Unternehmen. Daher werden alle vorhandenen Informationen automatisch analysiert (mittels eines statistischen Documentenclusterings durch niederfrequente Terme, vgl. [QW00]) und wird für jede Information eine Meta-Information generiert, die den Bezug der Information zu den Inhalts- und Kontextontologien darstellt. Das gleiche Verfahren kann auf explizite Informationsbedarfsformulierungen (klassisch: „Suchabfrage“) eines Benutzers angewendet werden. Bezüglich konkreter Aufgaben sind auch damit nur Teile der Gesamtontologien relevant; So können auch sie meta-indexiert werden. Technisch gesehen wird die Informationsversorgung dann durch ein Matchingverfahren zwischen diesen diversen Meta-Informationen (Siehe Abbildung 1) realisiert. Die Meta-Informationen werden in den Formalismen und Formaten des Semantic Web formuliert, wie vorgeschlagen von W3C.
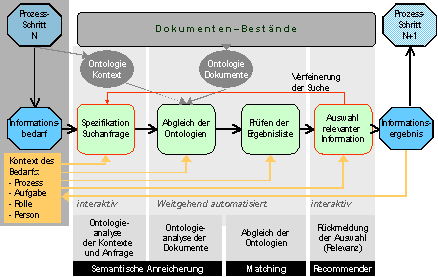
Abbildung 1: Ablauf einer Benutzerinteraktion
Auf der funktionalen Ebene besteht das System aus drei Hauptkomponenten, die mit der Wertschöpfungskette der Einführung und des Betriebs des Systems: „Structure“, „Fill“ und „Use“ (Siehe Abbildung 2) korrespondieren. Im Sinne der Informationsversorgung wird zuerst eine Ordnungsstruktur für die Informationen zurechtgelegt. Anschließend wird diese Struktur mit den zur Verfügung stehenden Informationen „befüllt“. Das „befüllte“ System der strukturierten Information bietet an geeigneter Stelle die richtige Information.
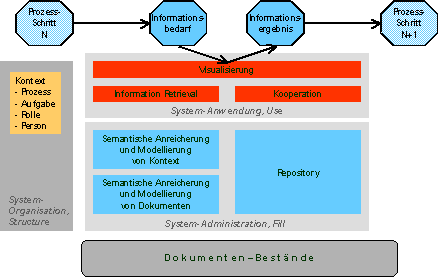
Abbildung 2: Funktionale Architektur des PREBIS Systems
Die Structure-Komponente wird sowohl für den Aufbau gebraucht, als auch für den Betrieb sowie die Pflege und Organisation der Inhalts- und Kontextontologien. Die Fill-Komponente bildet das Kernsystem im Backend. Hierin werden die vorhandenen Informationen/Dokumente analysiert und Meta-Informationen (Inhalts- und Kontextbezüge) gemäß Elemente aus „Structure“ generiert. Diese „Anreicherungen der Dokumente sind in einem Repository zu halten. Die Use-Komponte stellt im weitesten Sinne die Benutzungsschnittstelle dar. Hier sind Funktionalitäten des Information Retrieval (Navigation, Bedarfsformulierung) kombiniert mit Verfahren der Bewertung der Suchresultate vorzufinden. Im Projekt wird im Besonderen an der Visualisierung der Navigation und Ergebnispräsentation sowie an die Integration von Kooperationsverfahren (Recommendersysteme u.d.) gearbeitet.
Zusammenfassung
Im vorliegende Beitrag wurden die Zielsetzung und die Forschungsthemen des laufenden Projektes PREBIS vorgestellt. Zur Erreichung einer rollen- und aufgabengerechten Informationsversorgung in Unternehmen wurde die Geschäftsprozessmodellierung in Verbindung mit Textanalyseverfahren zur Erstellung von unternehmensspezifischen Ontologien behandelt Anschließend wurde eine erste funktionale Architektur des zu entwickelnden PREBIS-systems vorgestellt. PREBIS soll den potenziellen Kunden später als System geliefert werden, das bereits Referenz-Geschäftsprozessmodelle beinhaltet (z.B. Recherchestrategien und bekannte externe Informationsquellen) und dann auf den unternehmensspezifischen Bedarf und vorliegende Strukturen angepasst wird (Unternehmensspezifische ontologische Teilmodelle). Damit sollen kostengünstige Lösungen insbesondere für kleine und mittelständische Unternehmen (KMU) ermöglicht werden. Mit ersten konkreten Ergebnissen des Projektes ist Anfang nächsten Jahres zu rechnen. Weitere Informationen zum Projekt sind abrufbar unter http://www.prebis.de.
Literatur
[ALS02] Apitz, René, Andreas D. Lattner, Christian Schäffer (2002): Kontextbasiertes Wissensmanagement in der Produktentwicklung als Grundlage für anpassungsfähige Unternehmen. In: Industrie Management, Heft 3, S. 32-35.
[BHL01] Berners-Lee, T. Hendler, J., and Lassila, O. (2001): The Semantic
Web. A new form of Web content that is meaningful to computers will unleash a
revolution of new possibilities, In: Scientific American, Issue May 2001. Online Version zugänglich unter
http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
[Br01] Brickley, D. (2001): RDF(S) web service for WordNet 1.6, abrufbar unter http://xmlns.com/2001/08/wordnet/
[CCM01] Web Services Description Language (WSDL) 1.1 W3C Note 15 March 2001: Erik Christensen, Microsoft, Francisco Curbera, IBM Research, Greg Meredith, Microsoft, Sanjiva Weerawarana, IBM Research, abrufbar unter http://www.w3.org/TR/wsdl
[De02] Dengel, Andreas, Andreas Abecker, Ansgar
Bernardi, Ludger van Elst, Heiko Maus, Sven Schwarz, Michael Sintek (2002):
Konzepte zur Gestaltung von Unternehmensgedächtnissen. In: Künstliche
Intelligenz, Heft 1, S. 5-11.
[FG02] Franken, Rolf, Andreas Gadatsch (Hrsg.,
2002): Integriertes Knowledge Management. Konzepte,
Methoden, Instrumente, Fallbeispiele.
[FWW02] Fillies, C., Wood-Albrecht, G., Weichhardt, F. (2002): A Pragmatic
Application of the Semantic Web Using SemTalk, WWW2002, May 7-11, 2002,
Honolulu, Hawaii, USA ACM 1-5811-449-5/02/0005
[GM02] R.V.Guha, Rob McCool (2002):A System for integrating Web Services into a Global Knowledge Base, abrufbar unter http://tap.stanford.edu/sw002.html
[HL01] Heyer, Läuter, Quasthoff, Wittig, Wolff
(2001): Learning relations using collocations, in: A.
Maedche, S. Staab, C. Nedellec and E. Hovy, (eds.). Proc. IJCAI Workshop on
Ontology Learning,
[Ja02] Jarke, Matthias (2002): Wissenskontexte.
In: Künstliche Intelligenz, Heft 1, S. 12-18.
[KB02] Kwan, M, Balasubramanian, P. (2002): KnowledgeScope: managing knowledge in context. In: Decision Support Systems (in press, abrufbar unter http://www.sciencedirect.com/science)
[KF89] Krallmann, Herrmann; Feiten, L.; Hoyer, R.;
Kölzer, G. (1989): Die Kommunikationsstrukturanalyse (KSA) - Zur Konzeption
einer betrieblichen Kommunikationsarchitektur, in: Kurbel, K.; Mertens, P.;
Scheer, A.W. (Eds.): Interaktive betriebswirtschaftliche Informations- und
Steuerungssysteme, Berlin.
[KW00] Kuppinger, Martin, Michael Woywode (2000): Vom
Intranet zum Knowledge Management. Die Veränderung der Informationskultur in
Organisationen. München.
[NTB01] Nonaka, Ikujiro, Ryoko Toyama, Philippe
Byosière (2001): A Theory of Organizational Knowlegde Creation: Understanding
the Dynamic Process of Creating Knowledge. In: Meinolf Dierkes, Ariane B.
Antal, John Child, Ikujiro Nonaka (Hrsg.): Handbook of Organizational Learning
and Knowledge.
[OWL02] Dean, M. Connolly, D., van
Harmelen, F., Hendler, J., Horrocks,
[QW00] Quasthoff, Uwe., Wolff, Christian. (2000): Effizientes Dokumentenclustering durch
niederfrequente Terme. Abrufbar unter:
http://wortschatz.uni-leipzig.de/Papers/Dokumentenclustering.pdf