Dezentrale Modellierung und Entwicklung eines Data Warehouse für eine Krankenkasse
Dr. Monika Bulst
AOK Berlin
Dr. Frauke Weichhardt
beratung im netz
Zusammenfassung
Im Rahmen der Verbesserung der Analysemöglichkeiten
der Daten wurde im Jahr 2000 mit der Einführung eines Data Warehouse in der AOK Berlin begonnen. Ziel dieses
Projekts war die Schaffung grundlegender Strukturen für den Aufbau und den
Betrieb des Data Warehouse. Dabei mussten die konkreten
Auswertungsanforderungen der betroffenen Bereiche sowie die in der AOK
vorliegende Organisationsstruktur berücksichtigt werden. Um eine so komplexe
und abstimmungsintensive Aufgabe unter Einsatz möglichst geringer
Personal-Ressourcen lösen zu können, musste ein Weg gefunden werden, die
notwendigen Mittel dezentral bereitzustellen. Entstanden ist dabei eine
dezentrale organisatorische Struktur des Data Warehouse, die auf den Austausch
des entstehenden Wissens zwischen den einzelnen Bereichen angewiesen ist. Der
vorliegende Artikel beschreibt die entstandene Struktur sowie den Einsatz von
1.
Einleitung
Die AOK Berlin steht im Wettbewerb
mit anderen Krankenkassen. Aus diesem Grund muß vermehrt Wert auf eine gute
Steuerung des Unternehmens gelegt werden. Wesentliche Voraussetzung dafür ist
insbesondere eine einheitliche Sicht auf die Daten des Unternehmens. Für die
Schaffung eines Systems, das dies leisten kann, wurde eine Data Warehouse
Architektur aufgebaut. Entwicklung und Einführung vollziehen sich schrittweise,
so daß sich die Belastung der beteiligten Mitarbeiter in Grenzen hält.
Gleichzeitig muß berücksichtigt werden, daß die einzelnen Unternehmensbereiche
der AOK Berlin ihre Daten vergleichsweise autark bewirtschaften. Die
IT-Abteilung hat nur begrenzte Personalressourcen zur Verfügung und ist auf
eine Zusammenarbeit mit den Bereichen in
personeller und fachlicher Hinsicht angewiesen. Aus diesem Grund wurde eine
dezentrale Struktur geschaffen, die kurze Wege zwischen Benutzern und
Entwicklern sicherstellt sowie trotz der dezentralen Struktur des Unternehmens
eine hohe Akzeptanz des Systems gewährleistet, da Benutzer ihre Anforderungen
direkt einbringen können.
In diesem Artikel wird zunächst die Ausgangssituation des Unternehmens beschrieben. Darauf aufbauend wurde die Vorgehensweise entwickelt, die im darauf folgenden Abschnitt beschrieben wird. Die dabei entstandene Organisationsstruktur beschreibt der vierte Abschnitt. Im Rahmen des fünften Abschnitts „Wissenstransfer“ wird gezeigt, wie die im Data Warehouse verwendeten Informationen beschrieben werden, so daß sich Benutzer und Entwickler schnell ein Bild über Grundlagen und Zusammenhänge der verwendeten Daten machen können. Die dabei verwendete Technologie der Modellierung auf Basis von Semantic-Web-Technologien wird im Abschnitt sechs dargestellt.
2.
Ausgangssituation
Die Situation der AOK ist durch folgende Faktoren
gekennzeichnet:
Es dominieren historisch gewachsene Datenstrukturen.
Auf der zentralen Datenbank hat jede Abteilung ihren eigenen Bereich und
betreibt eigene Auswertungen. Zusätzlich gibt es weitere Legacy-Systeme, die
von den einzelnen Bereichen autark bewirtschaftet und mit dem zentralen System
abgeglichen werden.
In den Unternehmensbereichen und Fachabteilungen sind
im Laufe der Zeit eine Reihe eigener Anwendungen entstanden. Diese Anwendungen
basieren größtenteils auf MS Access oder MS Excel. Die dafür benötigte
Datenbasis wird in der Regel lokal auf dem PC des Anwenders oder auf einem
File-Server gehalten (Abteilungsdatenbestände). Sie werden auf der Basis von
Rohdaten aus dem Legacy-System oder anderen externen Daten erstellt.
Eine Integration der Datenbestände erfolgte bisher
nicht.
Die wirtschaftliche Situation der AOK Berlin bedingt
die Anforderung einer hohen Anzahl von Auswertungen in allen Bereichen und im
Vergleich zu anderen Bundesländern. Auf diese Anforderungen muß häufig sehr
schnell reagiert werden. Die betroffenen Mitarbeiter konnten diese
Anforderungen bisher entweder gar nicht oder nur unter sehr hohem persönlichen
Einsatz erfüllen. Die ihnen zur Verfügung stehenden Systeme konnten die
notwendige Flexibilität in der Regel nicht bieten.
3.
Vorgehensweise
Voraussetzung für die Durchführung des Projekts war
die Unterstützung durch die Geschäftsleitung in Form von fachlicher
Schirmherrschaft durch ein Mitglied der Geschäftsleitung und technischer
Betreuung durch den Leiter der IT-Abteilung. Diese zwei Personen bildeten auch
den Steuerungsausschuß im Rahmen der Leitung des Projekts. Mit ihrer Hilfe
wurden zunächst zwei Unternehmensbereiche als Pilotanwender gewonnen. Deren
Auswertungsanforderungen wurden analysiert, um die notwendigen Kennzahlen und
Dimensionen zu ermitteln. Auf dieser Basis wurden schrittweise Datenwürfel und
zugehörige Data Marts entwickelt sowie standardisierte Reports. Diese basierten
im ersten Schritt weiterhin auf den Abteilungsdatenbeständen. Im Anschluß wurde
die Datenlogistik für die Verwendung der zentralen Datenbestände erarbeitet.
Schließlich wurden zentrale und dezentrale Bestände innerhalb der Data Marts
integriert.
Die Bewirtschaftung des Systems wurde durch die
Entwicklung und Umsetzung eines Betriebskonzepts sichergestellt. Dazu gehörte
auch die Bereitstellung eines Änderungsdienstes sowie der Aufbau der
notwendigen IT-Infrastruktur (Aufbau der Server-Systeme, Installation der
Clients, Benutzeradministration, Berichtsportal) und der Durchführung von
Schulungen für Entwickler und Benutzer.
Inzwischen nehmen fünf Unternehmensbereiche an dem
Projekt teil (Vertrieb, Vertragsmanagement, Unternehmensplanung, Personal,
Krankenhausmanagement). Eine weitere schrittweise Ausweitung ist angedacht.
4.
Organisationsstruktur
Hier werden zunächst die für das System notwendigen
Gremien und Instanzen sowie deren Zusammenarbeit beschrieben. Vorgesehen ist
eine dreistufige Nutzung des Systems: Dabei wird davon ausgegangen, daß es im
Fachbereich einerseits Entwickler für die Datenwürfel gibt (Würfel-Verantwortliche)
bzw. Bereichsvertreter dazu, dann die Controller als „Power User“, die
selbständig mit den Inhalten der Würfel arbeiten und Berichte erzeugen sowie
die Endanwender, die „Konsumenten“ der Ergebnisse der Controller. Sie
manipulieren nicht selbständig in den
Daten, sondern lesen und verwenden die erzeugten Berichte. Bei Bedarf können
auch diesen Endanwendern Datenwürfel zur eigenständigen Analyse zur Verfügung
gestellt werden.
Die Implementierung erfolgt themenbezogen innerhalb von
Teilprojekten. Diese arbeiten definierte Anforderungen ab und stellen die
Bewirtschaftung der entsprechenden Daten sicher.
Folgende Gremien und Instanzen wurden im Rahmen der
Systemeinführung geschaffen:
Das gesamte System wird durch zwei Koordinatoren
betreut. Diese kommen einerseits aus dem Fachbereich Controlling (fachliche
Koordination) und andererseits aus dem IT-Bereich (technische Koordination) und
bilden damit ein interdisziplinäres Team. Sie stellen ein einheitliches
Projektvorgehen, eine einzige technische Systemumgebung (Entwicklungs-, Test-
und Produktionssystem) und einen einheitlichen Modellansatz sicher.
Als zentrales Projektgremium wurde ein Kernteam
geschaffen, in dem Entwicklungen und Aufgaben abgestimmt werden. Das Kernteam
wird durch die Koordinatoren geleitet und moderiert. Weitere Mitglieder sind
die Würfelverantwortlichen sowie der Dokumentationsverantwortliche (s.u.). Das
Kernteam ist für die Projektkoordinatoren das zentrale Instrument zur
Sicherstellung eines einheitlichen Projektvorgehens, einer einzigen technischen Projektumgebung
und eines einheitlichen Modellansatzes.
Der Dokumentationsverantwortliche ist für die
Aktualisierung und Pflege der Systemdokumentation verantwortlich, insbesondere
für die Beschreibung der verwendeten Kennzahlen und Dimensionen im
sogenannten Datenkatalog und für das
Datenmodell. Der Dokumentationsverantwortliche wurde zunächst durch ein
Redaktionsteam unterstützt, das innerhalb der Anlaufphase des Projekts die
anfänglichen Datenquellen zu den ermittelten Kennzahlen und Dimensionen sowie
mögliche Standardisierungen zwischen den einzelnen Bereichen erarbeitete.
Je Teilprojekt wurden zwei Würfel-Verantwortliche
etabliert, die sich gegenseitig vertreten können. Die Würfel-Verantwortlichen
dienen als Schnittstelle zwischen Fachbereich und zentraler IT-Abteilung. Sie
vertreten ihren Bereich auf Dauer im Kernteam und müssen die im Kernteam
erarbeiteten Abstimmungen/Standards innerhalb ihres Bereiches umsetzen. Dazu
arbeiten sie eng mit den jeweiligen Controllern und sonstigen Anwendern
zusammen. Außerdem leisten sie First-Level-Support für alle ihre Anwender.
Die Würfel-Verantwortlichen überwachen die
Datenqualität ihrer Würfel und stoßen im Rahmen des Kernteams notwendige
Änderungen an. Für in ihrer Verantwortung befindliche Daten müssen sie die
notwendigen Maßnahmen zur Sicherstellung der Datenqualität durchführen bzw.
koordinieren. Häufig haben sich um die Würfel-Verantwortlichen Würfel-Teams
gebildet, die die Entwicklung und Wartung der Würfel durchführen.
Alle Würfelverantwortlichen treffen sich unter der
Ägide der Projekt-Koordination regelmäßig, um gemeinsame Datenbestände auch
wirklich gemeinsam nutzen zu können. Sie gehören fachlich und disziplin
Kann diese Form der Zusammenarbeit (dezentrale
Variante) aufgrund mangelnder Personalressourcen im jeweiligen
Unternehmensbereich nicht durchgesetzt werden, wird von den betroffenen
Unternehmensbereichen dauerhaft ein fachlicher Vertreter (Bereichsvertreter)
für das Data Warehouse benannt. Die Würfelverantwortlichen werden dann durch
den IT-Bereich zur Verfügung gestellt (zentrale Variante). Sie müssen intensiv
mit den Bereichsvertretern zusammenarbeiten.
Die Bereichsvertreter sind ebenfalls Mitglieder des
Kernteams. Es muß beobachtet werden, in welchem Maß die damit erhöhte Zahl der
Mitglieder die Arbeitsfähigkeit des Teams einschränkt, insbesondere für den
Fall der Einbeziehung weiterer Unternehmensbereiche in das System.
Gegebenenfalls muß die Zusammenarbeit zwischen Kernteam und Bereichsvertretern
auf andere Weise durchgeführt werden.
Der IT-Bereich stellt mit Hilfe des ETL-Teams die
Datenlogistik sicher. Hier wurde auch das Betriebskonzept erarbeitet sowie die
Modellierung der Datenbasis durchgeführt. Außerdem erfolgt hier der
Second-Level-Support für die Anwender. Mittelfristig wird diese
Anwender-Unterstützung durch den zentralen Benutzer-Support der AOK Berlin
geleistet werden. Einer der Projekt-Koordinatoren entstammt dem IT-Bereich, der
die Abstimmung und Koordination der Aktivitäten der Würfelverantwortlichen auf
technischer Ebene und mit dem ETL-Team durchführt. Hier wird auch die
Dokumentation gewartet bzw. aktuell gehalten, ist also der
Dokumentationsverantwortliche angesiedelt. Bei entsprechendem Anlaß führt diese
Stelle zusätzliche Abstimmungen herbei, wenn es um die Veränderung der
Datenstrukturen innerhalb der Grunddaten oder innerhalb der Data Marts geht.
Die Controller in den Fachbereichen erstellen die
Standardberichte. Sie werden dabei von den Würfelverantwortlichen unterstützt
und im Kernteam vertreten. Würfelverantwortliche und Bereichsvertreter arbeiten
gegebenenfalls mit Arbeitsteams ihrer Bereiche zusammen, in denen mögliche
Lösungen der spezifischen Auswertungsproblematiken oder neue Anforderungen
diskutiert werden können. Je nach spezifischer Organisation des jeweiligen
Bereichs treffen sich die Mitglieder dieses Arbeitsteams regelmäßig oder werden
individuell durch den Würfelverantwortlichen angesprochen.
Im zentralen Controlling sitzt der andere
Projekt-Koordinator, der die Aktivitäten der Würfelverantwortlichen fachlich
koordiniert. Er sorgt mittel- bis langfristig für eine Vereinheitlichung der
verwendeten
Beide Personen gemeinsam verantworten das System,
einer davon als Stellvertreter. Sie berufen das Kernteam ein, bereiten es vor
und moderieren.
Die hier genannten Aufgaben werden auch über die
Einführungsphase hinaus wahrgenommen. Innerhalb des Betriebskonzepts und des
Change Management-Konzepts wurden dazu die entsprechenden
Aufgabenbeschreibungen und Geschäftsprozesse definiert, so daß auf dieser
Grundlage die notwendige Veränderung der Organisationsstruktur stattfinden
konnte.
Es ergibt sich also folgende Aufgabenverteilung:
Gesamtprojektkoordination: zwei Personen; je einer aus
dem IT-Bereich und aus dem zentralen Controlling
Würfelverantwortliche/Würfel-Teams: je Themengebiet
mindestens zwei Personen aus den beteiligten Fachbereichen als Entwickler der
Würfel und für die Unterstützung der Controller bei der Bereitstellung der
Standard-Berichte
Bereichsvertreter: Falls die Würfelverantwortlichen
nicht aus dem Unternehmensbereich kommen, stellt der betroffene Bereich zwei
Bereichsvertreter. Diese arbeiten an den
notwendigen Aktivitäten mit: Teilnahme an Kernteam-Sitzungen, Beratungen und
Maßnahmenplanung im eigenen Bereich zu Umsetzung und Änderung von
Projektinhalten, Abstimmung mit Würfelverantwortlichen.
Arbeitsteam: Abstimmung und Zuarbeit innerhalb der
Unternehmensbereiche; Größe je nach Bedarf
Dokumentationsverantwortlicher: Wartung und
Aktualisierung der Dokumentation (Datenkatalog und Berichtsstruktur; ggf. Datenmodell):
eine Person aus dem IT-Bereich.
Redaktionsteam: Unterstützung des
Dokumentationsverantwortlichen in der Phase der Datendefinition bei der
Ermittlung von Datenquellen und Standardisierungsmöglichkeiten.
ETL-Team: Erarbeitung der zentralen Datenlogistik, der
Integration dezentraler Datenbestände und des Betriebskonzepts, Modellierung
der zentralen Datenbasis: drei Personen aus dem IT-Bereich; eine davon als
Unterstützung für notwendige Konzepte und Recherchen im Rahmen der
Dokumentationsaufgaben und der Datenbeschaffung.
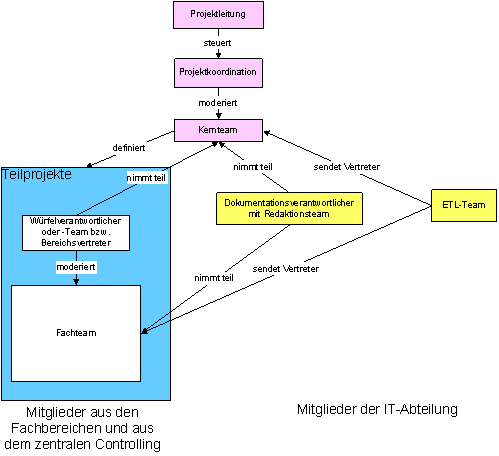
Abbildung 1: Organisationsstruktur des Data Warehouse
Projektleitung:
Projektaufsicht und Einflußnahme im Rahmen von Leitungsausschüssen
Kernteam: AOK-weite Koordination
der Teilprojekte und des Betriebs im Hinblick auf Synergien zwischen einzelnen
Bereichen
Projekt-Koordination:
Das Kernteam wird von den Projekt-Koordinatoren geleitet und moderiert.
Teilprojekte:
Konzepterstellung, Umsetzung und Überführung in Betrieb für einzelne definierte
Fachthemen
Fachbereiche und
zentrales Controlling: Mitarbeit in Kernteam und Teilprojekten
IT-Abteilung:
Bereitstellung der Infrastruktur für die Teilprojekte und deren Betrieb, Aufbau
der zentralen Ressourcen für das Data Warehouse
5.
Wissenstransfer
Die dargestellte Struktur
ermöglicht ein flexibles und zeitnahes Eingehen auf den Bedarf der
Fachbereiche. Gleichzeitig ist damit jedoch auch ein höherer
Koordinationsaufwand verbunden, um die Konsequenzen möglicher Veränderungen des
Gesamtsystems weiterhin beurteilen zu können. Um diesen Aufwand möglichst
niedrig zu halten, wurde folgende Unterstützung vorgesehen:
- Einrichtung eines Portals für das Data Warehouse
im Intranet der AOK Berlin
Das Portal ermöglicht den Zugriff auf vordefinierte Berichte, News und ein Forum, in dem Entwickler und Anwender Fragen zum System stellen können. Hier ist auch der Einstiegspunkt für den Änderungsdienst sowie der Zugang zur Dokumentation des Systems einschließlich der Würfelsteckbriefe und des Datenkatalogs. - Schaffung einer Community
Durch die Etablierung des Kernteams und der zugehörigen Arbeitsteams wurde eine Kommunikationsstruktur geschaffen, die auch quer zu den einzelnen Bereichsgrenzen funktioniert und so den Wissensaustausch nicht nur zu dem hier betrachteten System ermöglicht. Sie stellt ein zentrales Element zur Wartung und Weiterentwicklung des Gesamtsystems dar. Außerdem gewährleistet sie für die User kurze Wege zu ihrem jeweiligen Ansprechpartner und eine schnelle Umsetzung notwendiger zentraler Maßnahmen in den einzelnen Bereichen. - Dezentrale Erstellung des Datenkatalogs
Der Datenkatalog wird dezentral durch die einzelnen Entwickler erstellt und im Portal veröffentlicht. Verwendet wird derzeit ein Dokument aus Word-Tabellen. Um das System am Leben zu erhalten, muß der Datenkatalog ständig aktualisiert werden. Dies ist mit der derzeitigen Technologie sehr aufwendig. Im Test befindet sich eine graphische Darstellung, die die Wartung des Katalogs deutlich vereinfachen könnte.
Geplant ist hier die Erarbeitung von Modellen der Kennzahlen, Dimensionen,
Würfel und Berichte in graphischer Form. Dies geschieht mit Hilfe eines
Modellierungstools, das Technologien des
Der Dokumentationsverantwortliche bildet die
definierten Kennzahlen und Dimensionen in einem gaphischen Modell ab. Erfaßt
werden dabei auch
Namenskonflikte werden über Synoym-Routinen und ein
Namensraumkonzept gelöst (s. Abschnitt 6), so daß alle Bereiche auch ihre
eigenen Begriffe weiterverwenden können, wenn es zu Überschneidungen kommen
sollte.
Würfel und Berichte, die hier nicht dokumentiert sind,
haben keinen Anspruch auf Rücksichtnahme bei allfälligen Versionswechseln oder
sonstigen Wartungsarbeiten.
Auf diese Weise ergibt sich die Möglichkeit,
Datenmodelle und die Darstellung der Inhalte miteinander zu verknüpfen, ohne
alle Informationen erneut eingeben zu müssen. Über die Erzeugung von Code aus
den Modellen wird derzeit diskutiert.
6.
Semantisches Web und Data Warehouse
Das
Obwohl das
Definitionen werden für
Kennzahlen und Dimensionen einheitlich bestimmt. Wenn derselbe Begriff in verschiedenen
Defintionen verwendet werden soll, kann dieser Konflikt über ein
Namensraumkonzept gelöst werden. Eine solche Definition wird in einem zentralen
Modell abgelegt und kann dann eindeutig per URI referenziert werden, wie z.B. http://www.aok.de/KHB#Krankenhausbehandlungsfälle. In diesem Fall werden zwei verschiedene Kennzahlen
in zwei verschiedenen Bereichen mit demselben Namen verwendet: einerseits die
Anzahl der Fälle für das Fallmanagement und andererseits die Anzahl der Fälle
für die Verhandlungen mit dem Krankenhaus. Für die Verhandlungen mit dem
Krankenhaus ist die Berechnung fachabteilungsbezogener
Daten gesetzlich geregelt. Vergleichsdaten der AOK Berlin müssen nach den
gleichen
Interne Verlegungen werden in
den Berechnungen entsprechend dem Gesetz berücksichtigt.
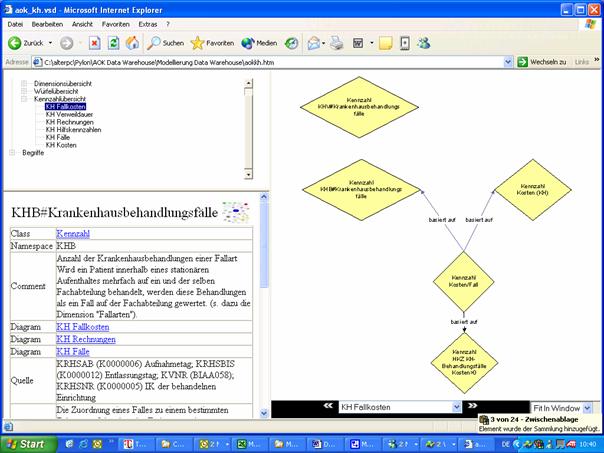
Abbildung 2: Beispiel für die
Darstellung des Datenkatalogs im Intranet auf Basis des
Bei der Berechnung
fachabteilungsbezogener Daten des Krankenhauses für das Fallmanagement werden interne
Verlegungen nur
fachabteilungsübergreifend berücksichtigt, da im Fallmanagement der Fall
ganzheitlich betrachtet werden muß. Nur so lassen sich Ansatzpunkte für das
Fallmanagemant ableiten, da bei Betrachtung nur aus der gesetzlich definierten
Sicht die durchschnittliche Verweildauer und die durchschnittlichen Kosten je
Fachabteilung geschönt werden.
Für das Data Warehoues mußten
also zwei verschiedene
Kennzahlen und Dimensionen
werden in ihren jeweiligen Zusammenhängen mit ihren
Die Verwendung von
7.
Fazit
Mit der Einführung des Data
Warehouse hat sich die AOK Berlin eine zeitgemäße Möglichkeit der Datenanalyse
geschaffen, die die Unternehmenssteuerung in wesentlichen Punkten unterstützen
kann. Gleichzeitig hat sie mit diesem Instrument einen wesentlichen Beitrag zur
Verbesserung der Kommunikationsstruktur im Unternehmen geleistet.
8.
Literatur
|
Tim Berners-Lee, Jim Hendler, and Ora Lassila published an article about
the Semantic
Web in Scientifc
American. "A new form of Web content that is meaningful to
computers will unleash a revolution of new possibilities". http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html |
|
Weichhardt,
F.; Fillies,C.: The |
|
Fillies,
C., Wood-Albrecht, G., Weichhardt, F., A Pragmatic Application of the |