Neue
Herausforderungen für ProzessmodellierungsWerkzeuge durch
und
das Semantic Web
Christian Fillies
Fillies & Friends Consulting, cfillies@cfillies.de
Dr.
Frauke Weichhardt
beratung im netz, fweichhardt@fweichhardt.de
Gabriele
Koch-Süwer
Gedion GmbH, Gabriele.Koch-Suewer@gedion.com
Einleitung
Grundlegendes
Thema des Wissensmanagements ist der Austausch von Wissen. Dabei ist sowohl die
Beschaffung fremden, neuen Wissens als auch die Bereitstellung eigenen Wissens
mit Problemen behaftet. Die Wissensbeschaffung wird in der Regel durch die
große Menge an zur Verfügung stehendem Wissen erschwert, da das relevante
Wissen dann in der Vielzahl der verfügbaren Informationsobjekte nicht mehr
gefunden wird. Es handelt sich hierbei also vornehmlich um ein
Navigationsproblem, das durch geeignete Indizierung der Objekte, welchedie
die Assoziationen des Benutzers und damit dessen Suchzusammenhang
nachempfindet, gelöst werden könnte. Diese Indizierung wiederum
muss schonß
bei der Bereitstellung erfolgen und bereits zu diesem Zeitpunkt mögliche
Suchzusammenhänge in der Zukunft voraussehen, also alle Konzepte erkennen,
die das Objekt enthält oder mit denen es im Zusammenhang steht,
erkennen.
Werkzeuge,
die das Wissensmanagement unterstützen, widmen sich derzeit hauptsächlich der
Auflistung vorhandener Wissensobjekte; eine echte Klassifizierung und
Indizierung bleibt meist dem Benutzer überlassen. Dies erzeugt zusätzlichen
Aufwand, den der Benutzer in der Regel nicht aufbringen will oder kann, da er
den Prozeß behindern würdet,
für den er eigentlich verantwortlich ist. Eine Bereitstellung alles möglichen
Wissens erfolgt damit nicht in dem Maß, wie es die Investition in die
teure Technik eigentlich erfordern würde.
Aktuell wird
versucht, mit Hilfe der Prozeßorientierung innerhalb des Wissensmanagements
eine weitere Möglichkeit zur Klassifikation und Navigation anzubieten.,
die ....... Die hierfür benötigten Werkzeuge zur
Prozessmodellierung sind derzeit alle
nicht in der Lage, semantische Netze in einer Art zu erzeugen, die auch
Nicht-Informatiker leicht erlernen können. Dass heißtmit
sind diese Ansätze können derzeit
nicht erfolgreich sein, da die Aktualisierung der Modelle, die
für eine Nutzung erforderlich ist, nicht in einem akzeptablen Zeitraum
durchgeführt werden kann, denn. uUm
dieses zu erreichen, müsste der Benutzer selbst in der Lage sein, den Prozeß zu
aktualisieren. Dergleichenies
geschieht erfahrungsgemäß aber nicht, wenn die derzeit verfügbaren
Tools eingesetzt werden, da kaum ein Unternehmen es sich leistet, alle
Mitarbeiter in der Benutzung der Tools auszubilden bzw. der Aufwand der
Aktualisierung selbst bei guter Kenntnis des Werkzeugs immer noch so
hoch ist, dass er erheblichen Mehraufwand im Prozeß erzeugen würdet.
Zukünftige
Prozessmodellierung muß unter Einbeziehung des Semantic Web erfolgen, um damit
eine feste Grundlage für die inhaltliche Verbindung von DMS, Content
Management, ERP
Systemen, Prozessmodell und
Supply Chain Management sowie ggf. anderen Applikationen zu schaffen. Durch den
Bezug auf existierende Informationsmodelle im Semantic Web wird der Aufwand zur
Erstellung der Prozessmodelle und der Klassifikation der konkreten Objekte
erheblich reduziert. Gleichzeitig muss gewährleistet werden, dass die
Prozessmodelle als Wissensnavigator in die tagtäglichen Arbeitsoberflächen wie
Outlook oder
Notes integriert werden. Erfolgreich könnenwerden
aber auch hier nur Ansätze sein, die sowohl die Lesbarkeit und Verständlichkeit
von Prozessmodellen als auch das Handling der Werkzeuge stark verbessern. Die
Aktualität der Modelle kann nur sichergestellt werden, wenn die Wartung
dezentral erfolgt, also auf persönlicher Ebene des Nutzers. Dazu gehört dann
auch die Möglichkeit, die zugrundeliegenden Begriffssysteme selbst gestalten
bzw. erweitern zu können. Entsprechend kann nur ein insgesamt dezentraler Ansatz anwendbare Lösungen erzeugen.
Aktuelle Ansätze bei existierenden BPM Werkzeugen
Die
Standardideen zum Knowledge Management, die man bei marktführenden Prozessmodellierungswerkzeugen
findet, sind:
§
Wissenskategorien, die zur Ausführung von Funktionen
benötigt werden, als Datenquellen mit in die Prozesse
aufzunehmen
§
Wissenslandkarten als eigenen Diagrammtyp
§
Personalisierbares Enterprise Knowledge
Portal als Zugang
§
Der Prozess ist das Wissen, Referenzmodelle heißen jetzt
Wissensmodelle
§
Verteilte Modellierung
§
Historie ausgeführter Workflows
Statische Prozessmodelle
dienen dabei zur einfachen Navigation des Wissen und unterstützen nur sehr
wenig bei der konkreten Problemlösung, der Beantwortung der Kernfrage des
Wissensmanagements: "Wo kann ich das, was ich abliefern muss, kopieren und wie
komme ich am einfachsten dran?"
Es entstehen
meist als reines
HTML graphische ggf. auch personalisierbare Yellow-Page Systeme, die
dokumentieren. wWer ist
für eine bestimmte Aktivität verantwortlich ist und,
eventuell wer
hat sie schon einmal durchgeführt und
ähnliche Fragen können beantwortet werdenhat.
Auch die
Integration mit klassischen Workflow Systemen führt nur bedingt weiter, da die
Ausführung des Prozesses zwar Kontextinformationen liefert um den Suchraum
durch die Prozesshistorie einzuschränken, trotzdem die Bearbeitung eines
Vorgangs wie "Angebot erstellen" nur durch das Auffinden von Angeboten zum
selben Thema mit einer ähnlichen Technologie wesentlich verbessert werden kann.
Das im Prozess beschriebene Wissen wie man ein Angebot schreibt spielt nur ein
sehr untergeordnete Rolle.
Prozessorientiertes
Wissensmanagement wie es z.B. im ASAP Wissensmanagement System bei SAP
realisiert wird [1], basiert auf dem Zugang zu den
Dokumenten anhand der Prozessbeschreibungen und nicht auf der Durchführung der
Prozesse. Betrachtet man zum Beispiel ASAP, ein Leitfaden oder Prozess, wie man
SAP einführt und welche Dokumente dabei zu erstellen sind. Das Problem der
Anwender ist dabei aber nicht nur zum kleinen Teil
Wissen darüber wie man diesen Prozess ausführt, also fehlendes Wissen
Prozesswissenüber
den Prozess, sondern sie wollen an den Erfahrungen, welchedie
die bisherigen Anwender dieses Prozesses gemacht haben, zu partizipieren. Diese Erfahrungen
sind aber nicht im abgelaufenen Workflow, also nicht darin, wer was
wie lange gemacht hat, sondern in den Dokumenten oder Modellen, die während des
Prozesses erzeugt wurden zu finden. Leere Dokumentvorlagen sind
nützlich um schneller zu Ergebnissen zu kommen und um die Ergebnisse leichter vVergleichen
zu können, reichen aber bei weitem nicht aus.
Das Problem
ist herauszufinden, ob jemand schon einmal vor einer ein ähnlichens
Problem gehabtFragestellung
gestanden hat und wie er das gelöst hat, bzw. ob man da etwas abschreiben
kann. Das gilt für Beratungsprojekte genauso wie für ERP Einführungen. Wie
man einDie Durchführung eines Projektes durchführt,
über einen Workflow zu steuern, ist unserer Ansicht nach noch kein
wirkliches Wissensmanagement. Es gilt, das Wissen anhand von Prozessen und den
darin enthaltenen Informationsobjekten zu strukturieren und nicht nur an Hand
von Stichworten, wie es bisherige Systeme machen. Rohmaterial sind im
allgemeinen Dokumente, weniger oft Prozessmodelle und Organigramme selbst.
Ein
prozess-orientiertes Wissensmanagement-System benutzt dieselben Sprachmittel
und auch dieselben Begriffe zur Prozessbeschreibung und zur Beschreibung bzw. Indizierung der
Dokumentation.
Die meisten
GPO Werkzeuge beinhalten zur Zeit Diagramme zur Darstellung von UML
Klassenstrukturen. Die UML Klassen-Modelle werden im GPM Kontext im
Gegensatz zu CASE Tools nicht zur Softwarebeschreibung, sondern zur
Beschreibung von Informationsmodellen benutzt.
Die
Standardisierung durch UML ist zwar ein Gewinn an sich, macht
aber die allgemeine Verwendung für das Wissensmanagement in der Praxis
durch ihre relativ technische Notation sehr schwer. Gerade durch die
objekt-orientierte Softwarelastigkeit entstehen für die Wissensrepräsentation aber
auch erhebliche Nachteile gegenüber frame basierten Triplel -
Sprachen wie RDFS mit Relationen als eigenständigen Objekten und dem Wissensrepräsentationsaufsatz
OIL, die
Aussagen über Objekte
erlauben ohne die Definition der Objekte zu verändern..
Die nächste Generation von Prozessmodellierungswerkzeugen
wird den Fokus auf eine allgemein verständliche Wissensmodellierung statt auf
Standards des Software Engineering legen.
Die Entwicklung des Semantic Web
Der wichtige
Aspekt in diesem Umfeld ist die Entwicklung des Semantic Web. Semantic Web
bedeutet, dass die nächste Generation des WWW ein Web von Meta-Informationen
sein wird. Zusätzlich zum verlinkten Netz aus Texten entsteht ein Web aus
Meta-Informationen, formalisierten Beschreibungen des Inhalts von
Webdokumenten. Wichtig ist dabei, dass es kein zentrales Repository oder Kontrollinstanz
gibt. Jeder kann Aussagen über alles andere bilden. Sinnvoll ist es natürlich,
partiell konsistente Sprachen für diese Aussagen zu schaffen. Das Semantic
Web eröffnet ein enormes Potential für
neue Such- und Vergleichsmaschinen bzw. Agenten. Das klassische Beispiel ist
die CIA. Jeder der zigtausend Geheimagenten schreibt jeden Tag einen Bericht.
Wie schafft man es, aus diesen Berichten ein möglichst konsistentes wenn auch
teilweise widersprüchliches Bild der Lage zu ziehen ?
Im selben Anwendungsgebiet mit
der selben Sprache geschriebene Berichte sollten es ermöglichen, die richtigen
Schlussfolgerungen
zu ziehen.
Im letzten
halben Jahr hat die Anzahl der Tagungen und die Menge des
verfügbaren Contents für das Semantic Web deutlich zugenommen. Der W3C Standard
(RDF / RDFS )
ist inzwischen weitgehend stabilisiert. Die ersten Tools (z.B.
Protege-2000
der Stanford University oder OntoEdit der Ontoprise GmbH,)
sind als Open-Source vorhandenverfügbar. Ein große Anzahl
neuer Anwendungen ist in Kürze zu erwarten.
Das Semantic
Web unterstützt den dezentralen Ansatz, indem nicht nur ein
unternehmensweites Informationsrepository erzeugt wird, sondern analog zum
gegenwärtigen Internet die Möglichkeit geschaffen wird die Ressourcen des Web zur Modellierung zu
nutzen und gleichzeitig eigene Elemente zu definieren und zu etablieren [2]. In
der Endform führt dieses für den Benutzer zum "Personal Semantic
Memory".
Lösungen zur Integration des Semantic Web mit GPM
Wie kann man
mit RDFF,
der Sprache des Semantic Web Meta Wissen über den Inhalt von Prozessen bzw./
Projekten in einer sowohl dem Benutzer verständlichen als auch maschinell
verarbeitbaren Form repräsentieren?
Zur Zeit gibt
es noch keine End-User geeigneten Werkzeuge um einfache RDFS zu entwickeln.
Am weitesten
ist zur Zeit
das FRODO RDFSViz Tool des DFKI [3].
Wir entwickeln
zur Zeit einen Visio2000 basierten RDF Editor. Dieser Editor wird es den
Endanwendern, die auch die Prozessmodellierungswerkzeuge einsetzen,
ermöglichen innerhalb der MS-Office Welt auf einfache graphische Weise
Wissensmodelle zu entwickeln. Der Editor liest und schreibt eine Untermenge
von RDF / RDFS unter Benutzung des einfachen MSXML DOM API. In Zukunft kann
dieses Werkzeug auf OIL erweitert werden.
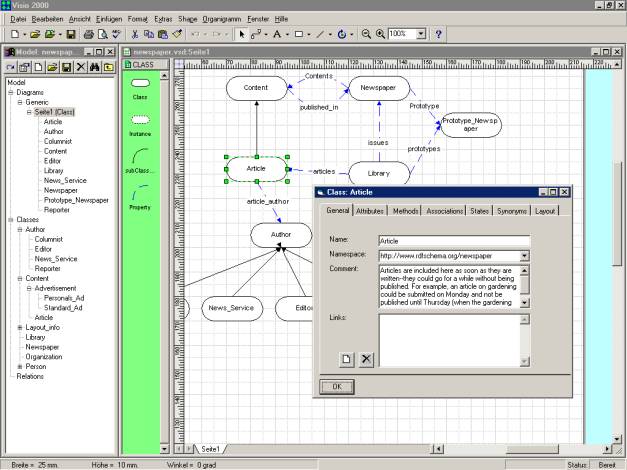
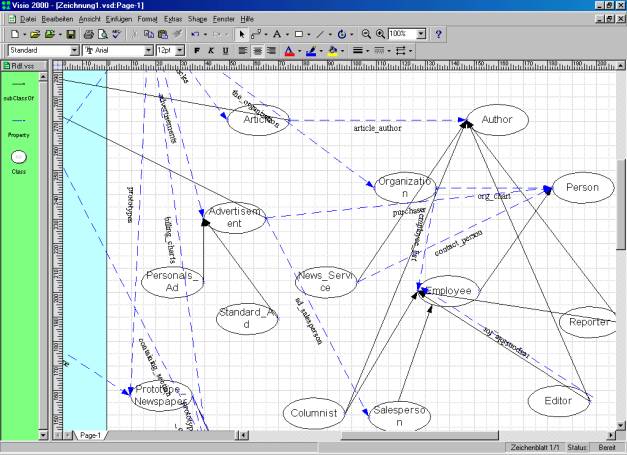
Screenshot einer Alpha
Version des RDF Editors
(da kommt noch ein besseres Bild hin wenn die
Russen etwas weiter sind J
)
Im nächsten
Schritt wird aber
eine tiefere Integration in Office Werkzeuge wie Outlook oder Word zur
Annotation von Dokumenten erfolgen müssen.
Wie kann man
es ermöglichen, dass die Taxonomien des Semantic Web in den Prozessmodellen
verwendet werden?
Exemplarisch haben wir für ein GPO
Werkzeug eine Schnittstelle zu WordNet dem bekanntesten Oonline
- RDF Repository entwickelt. WordNet ist zur Zeit ein Forschungsprototyp http://xmlns.com/ und darf (leider) nicht
für kommerzielle Zwecke eingesetzt werden. In Zukunft weirden jede
viele
RDF / RDFS -Datenquellen zu
Modellierung benutzt werden können. Umgekehrt werden aber bestehende GPO Modelle als
RDF/S Wissensquellen über entsprechende Webserver publiziert werden.
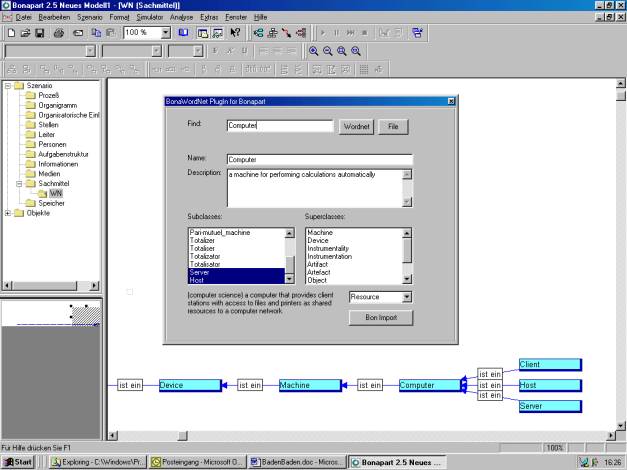
Die meisten
GPO Werkzeuge verwenden ein Repository von
Bausteinen bzw. Klassen zur Bildung von Prozessen. Diese Bausteine umfassen
Informationen, Funktionen, Sachmittel usw. Dieses Repository kann, wie im Bildhier
gezeigt, direkt aus den RDFS Schemata des Semantic Web
abgeleitet werden.
Auf diese
Weise wird kann eine
sprachliche und inhaltliche Verbindung zwischen Prozessmodellierung und den RDF
indizierten Dokumenten des neuen Webs
geschaffen werden. Durch die Verwendung des selben Schemas im Prozess z.B. als
Informationsmodell wie bei der RDF Indizierung Meta-Beschreibung
der Dokumente entsteht die Möglichkeit Dokumente mit
dem Kontext des Prozesses zu finden. Der folgende Abschnitt zeigt, wie daraus eine
prozessbasierte Wissensmanagement Arbeitsumgebung entstehen kann.
Integration von Vorgangsbearbeitung und Wissensmanagement
Die tägliche
Arbeit des Mitarbeiters orientiert sich - bewusst oder unbewusst - an den
Geschäftsprozessen des Unternehmens. Die Ausrichtung auf die Wertschöpfung und
damit auf die Kundenorientierung sollte Motivation und Zielvorgabe jedes
Mitarbeiters sein. Damit stehen die Geschäftsprozesse stets im Mittelpunkt des
unternehmerischen Handelns und bilden den idealen Zugang
zu notwendigen
Daten und Informationen, die angereichert mit Erfahrungen und Erkenntnissen,
kontextorientiertes Wissen für den konkreten Zusammenhang bereitstellen.
Davon ausgehend,
dass sich einerseits das "absolute" Wissen der Welt alle 5 Jahre verdoppelt,
aber andererseits das konkrete Wissen innerhalb von 3 Jahren bereits zu 50%
wieder überholt ist, wird klar, dass an die Methode der Prozessorientierung neue
Herausforderungen bzgl. Stabilität einerseits und Dynamik andererseits gestellt
werden
müssen.
Abstrakte,
stabile, das ganze Unternehmen beschreibende Geschäftsprozesse bilden das
Fundament des Wissensmanagements und werden mit konkreten, dynamischen, ggf.
nur Teilbereiche betreffenden Informationen angereichert. Zusätzlich wird die
Vernetzung und Kommunikation von Ressourcen für den Erfolg dezentraler,
interdisziplinärer Strukturen zur Voraussetzung, wenn Geschäftsmodelle wie Lean Management und
CRM funktionieren sollen.
Um dem Management
und den Mitarbeitern eines Unternehmens jetzt tatsächlich das richtige Wissen
zur richtigen Zeit am richtigen Ort zur Verfügung zu stellen, ist es notwendig,
sich sowohl abstrakt informierend als auch konkret ausführend vom
Wissensmanagementsystem unterstützen lassen zu können.
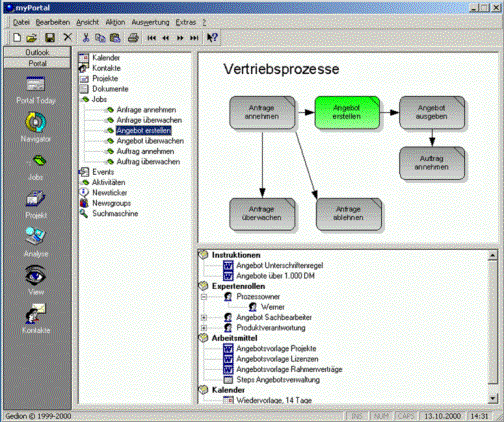
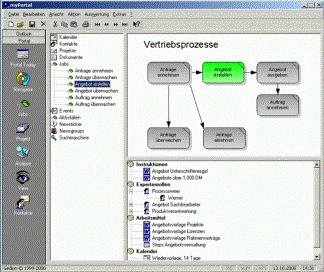
Screenshot des
gedion Prozessnavigators
Genau dies
leistet das gedionSystem u.a. mit seinem Prozessnavigator, dem persönlichen
Arbeitsplatz MyPortal und der Integration bestehender Anwendungen.
Die Aufgaben
eines Mitarbeiters - ggf. selektiert nach Rolle und/oder Geschäftsbereich -
werden im Prozessnavigator transparent in den gesamten Geschäftsprozess
eingeordnet. Hier erhält er die Informationen, die für ihn interessant sind,
wenn er z.B. diese Aufgabe das erste Mal oder selten ausführt. Welche
Informationen hier bereitgestellt werden, wird einerseits in
Organisationsprojekten erarbeitet und kann andererseits vom Mitarbeiter selbst
ergänzt werden.
Will er jetzt
konkret diese Aufgabe ausführen, muss die Integration in das tatsächliche
Arbeits- und Anwendungsumfeld erfolgen - muss EAI ( enterprise application
integration ) zur Realität werden. Die jetzt notwendigen konkreten
Informationen und Arbeitsmittel zur
Durchführung der konkreten Aktivität kommen aus dem Anwendungsumfeld des Mitarbeiter.
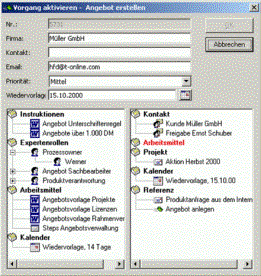
Instantiierung eines Prozesses
Damit wird
deutlich: auch wenn Technologien wie Internet und Intranet ungeheure
Entwicklungspotenziale für Unternehmen bereitstellen, sind sie "nur" Mittel zum
Zweck, aber nie Unternehmenszweck selbst. Die Ausrichtung der Geschäftsprozesse
einer Organisation auf die Wertschöpfung und Kundenorientierung und damit die
Ausrichtung der Mitarbeiter und ihrer Entscheidungen bleibt Aufgabe von Menschen und muss durch Technologien
und Anwendungssysteme ermöglicht, unterstützt und gefördert werden.
Organisationsentwicklung und Informationstechnologie gehören untrennbar
zusammen - ihre Schnittmenge ist der Geschäftsprozess.Der
ProzessNavigator von Gedion...
Das Prozessmodell als Navigationsinstrument durch den Wissensraum
Die Navigation
durch das Wissen innerhalb der betrachteten Domäne erfolgt derzeit entweder
über hierarchische Stichwortlisten oder über fremdbestimmte
Konzepterkennungssysteme. Der erste Ansatz hat den Nachteil, dass er bereits
bei leicht komplexen Hierarchien Suchprozesse stark in die Länge zieht, da viel
über trial and error gearbeitet werden muß. Der zweite Ansatz lässt den User in
der Regel mit einem Gefühl zurück, dass er vielleicht das, was er wirklich
gesucht hat, nicht angeboten bekommt, weil er den Prozeß der Suche nicht
verfolgen oder kontrollieren kann.
Für eine effektive
Suche ist die Bereitstellung von Kontextinformationen sehr sinnvoll, da ich
über Kontext stärker assoziativ suchen kann und damit ggf. schneller zum Ziel
komme, als wenn ich mich an genormte OntologienTaxonomien
halten muß. Eine Möglichkeit zur kontextsensitiven Suche bietet der Einsatz von
Prozessmodellen als Navigationsinstrument. In Zusammenhang mit der
Klassifikation von Objekten auf Basis des Semantic Web ergibt sich damit ein
Weg, taxonomische und kontextuelle Suche miteinander zu verbinden. Beispiel: Bei meiner Arbeit als Bauingenieur werde ich häufig vor die Aufgabe
gestellt, Behausungen verschiedenster Arten zu konstruieren. Will ich meine Arbeit innerhalb eines Wissensmanagement-Systems dokumentieren,
so bilde ich zunächst verschiedene Typen meiner Oberklasse "Behausungen", beispielsweise "Häuser für Menschen" und "Häuser für Tiere". Aus dem Semantic Web entnehme ich den ersten Vorschlag für die
Kategorisierungshierarchie meiner Objekte.
Ich
kann jetzt also die im
Rahmen meiner neuesten Entwicklung, des Baus eines Pinguinbeckens, entstandenen Dokumente und anderen Objekte mit Hilfe der bestehenden OntologieTaxonomie klassifizieren (lassen). Das System sagt mir, daß es den Begriff "Pinguin"
noch nicht gibt, und ich füge ihn ein. Damit habe ich das Semantic Web
erweitert. Mein Begriff kann eine einfache Erweiterung darstellen aber auch in
Widerspruch zu einer bereits bestehenden Definition stehen. Die Auflösung des
Widerspruchs erfolgt lokal bei jedem Nutzer.
Nach einem halben Jahr stellt sich
mir die Aufgabe, ein Giraffenhaus zu bauen. Ich suche in meinen alten
Aufzeichnungen, habe aber inzwischen so viele Kategorien unter "Häuser für Tiere", daß es mir keinen
Spaß machtr,
alle durchzusehen. Die Suchmaschine sagt mir, dassß es noch nichts über Giraffen gibt. Jetzt könnte
mir die Beschreibung des Prozesses, wie ein Haus gebaut wird, helfen. Ich könnte an den für mich relevanten Stellen des
Prozesses nachschauen, welche Dokumentation es bereits zu diesem jeweiligen
Schritt gibt. An dieser Stelle würde ich
wahrscheinlich auf meine alten Arbeiten für das Pinguinbecken stoßen. Diese geben
mir den Hinweis, welche behördlichen Schritte ich unternehmen muß, um überhaupt
eine Tierbehausung bauen zu dürfen, ich
finde dort die zugehörigen Formulare bzw. die bereits von mir ausgefüllten. Natürlich hilft mir die Berechnungsmethode für
das Pinguinbecken nicht weiter. Hinweise für das Haus selbst
finde ich vielleicht unter der Beschreibung des Elefantenhauses, das ich unter diesem Schritt
assoziativ entdeckt habe, da es von einem Kollegen entwickelt wurde, den ich
gar nicht mehr kenne, da er inzwischen pensioniert ist. Ich finde
dort eventuell sogar die Telefonnummer seines mir ebenfalls nicht bekannten Nachfolgers, der inzwischen die Abteilung
gewechselt hat. Bei konkreten Fragen
kann ich zumindest versuchen, mich an ihn zu wenden.
Die
Prozessmodelle erklären die Begriffe, und schaffen den gezielten Einstieg.
Durch
die Integration in die tägliche Arbeitsoberfläche steigt die Akzeptanz und
damit der Nutzen der Prozessmodelle.
Was hilft mir
das aber beim Angebotserstellungsprozess? Auf den ersten Blick erst mal nichts
solange der Prozess für alle Arten von Angeboten gleich ist. Wenn Angebote für
den Bau von Atomkraftwerken genauso erstellt werden wie Angebote für den Bau
einer Windkraftanlage, gibt es kein prozessorientiertes Wissensmanagement. Auch
ein detaillierter Angebotsprozess für Atomkraftwerke hilft nur beim Bau von weiteren
Atomkraftwerken.
Zusammenfassung
Die Prozessmodelle erklären die Begriffe, und
schaffen den gezielten Einstieg. Durch die Visio2000 basierte Editor Oberfläche
ermöglichen wir breiten Anwenderbereichen die Möglichkeit Wissensmodelle zu
erstellen. Anwendung der Wissensmodelle in
populären GPO Werkzeugen führt die Prozessmodelle als neues
Navigationsmedium in das Wissensmanagement ein. Durch die
Integration in die tägliche Arbeitsoberfläche steigt die Akzeptanz und damit
der Nutzen der Prozessmodelle und schafft insbesondere den Prozesskontext für
das intelligente Retrieval mit Hilfe des Semantic Web.
Das Semantic Web und generell XML
Schema im Allgemeinen z.B. aus
www.biztalk.org bieten aber neue
Möglichkeiten
für das prozessorientierte Wissensmanagement. Die Prozesse
können unter Berücksichtigung der TaxonomienOntologien entwickelt dokumentiert werden. D.h.
dass die Prozesse und Prozessvarianten abhängig von den OntologienTaxonomien
beschrieben werden. Damit
wird eine außerordentlich assoziative Möglichkeit des Suchens, damit des
Navigierens durch den Wissensraum geschaffen. Grundlage ihrer Anwendbarkeit ist
einerseits die Weiterentwicklung
und Nutzung des
Semantic Web und andererseits die Verbesserung der zur Verfügung stehenden Modellierungswerkzeuge
für Prozesse und RDFS.
Danksagung
Für die Entwicklung des Visio basierten RDFS Editors danken
wir Anton
V. Alexeyev,
Kostroma State
University
of Technology, GUS.
Literatur
[1] Volker Bach,
Dieter Blessing
Universität
St. Gallen, Institut für Informationsmanagement, CC BKM Competence Center
Business Knowledge Management (St. Gallen (Schweiz)):
"Strukturierung
von Projektwissen - Erfahrungen bei der SAP AG", http://www.KnowTech.net
[2] Staab, S., Angele, J., Decker, S., Hotho,
A., Maedche, A., Schnurr, H-P., Studer, S., Sure, Y.: AI for the Web ---
Ontology-based Community Web Portals. In: AAAI 2000/IAAI 2000 - Proceedings of
the 17th National Conference on Artificial Intelligence and 12th Innovative
Applications of Artificial Intelligence Conference, Austin/TX, USA, July
30-August 3, 2000, Menlo Park/CA, Cambridge/MA, AAAI Press/MIT Press. http://www.aifb.uni-karlsruhe.de/WBS/publications/
[3] DFKI RDFViz http://www.dfki.uni-kl.de/frodo/