Semantically correct Visio Drawings
Christian Fillies & Frauke Weichhardt
Semtation GmbH
Bob Smith
Tall Tree Labs
This paper
presents some use
We also present
a graphical notation for authoring OWL in Visio and discuss which part of
Description Logic can be expected to be used frequently.
1. Sem Talk
and Visio
It provides business
2. Modelling with a
corporate Sem antic Web
Only a small section of our users create OWL models for its own sake. In
most of the current models ontologies are used to normalize names of items in
models made for a different purpose than authoring OWL. Examples are the
Any existing OWL or RDFS source can be used as a repository or glossary
to ensure consistency. People often use lists of business
The resulting models are published in two ways: For end users graphical
representations of the models are published on the intranet as HTML, MS Word or
PowerPoint. For other modellers the model itself is available as a reusable
component, e.g. a process model to be refined with subprocesses or reused as a
process component. This makes all models a distributed web of knowledge.
Modelling of business processes and products in the context of a
distributed web of knowledge differs significantly from the way those models
have been created before. Before new terms are introduced, the user has to
investigate if the term or fact already exists in the community semantic web.
If the term already exists, the user model will reference that term by using
the same URN and providing an URL to obtain its definition. Existing terms may
be extended by subclasses or existing definitions of properties are added. If
the concept is identical but the current domain requires a different name, a
synonym can be added. For example a customer
will be called patient in a medical
domain.
The ontology contained, e.g. in a process is available for reuse in
different processes in the same domain. The most common use case of ontologies
in process modelling is to localize content to multiple languages. This is done
by translating objects in the ontology which will automatically generate
translated business processes.
Sometimes ontologies created for one specific purpose can be reused for
a new modelling problem in the same domain. For example a product catalogue
made for the web shop can be reused in a process modelling project.
3. Ontologies for Business
Processes as an example of light weight ontologies
The specification of business processes is a task executed by end users
or consultants who are often specialized on process optimization or ERP
systems. Those people are usually not educated in Description Logic and we do
not experience a lot of enthusiasm to learn about it in order to make “better”
ontologies.
For our purpose, which is ensuring consistency of other models, it is sufficient
to build taxonomies, sometimes enriched with properties in order to make them
more readable. Users have to learn about process modelling languages and a minimum
of object-oriented thinking in order to apply the ontologies to their process
models.
We use subclassing, DataProperties and ObjectProperties. For process
models we also add the list of valid verbs to the classes.
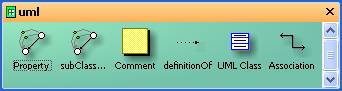
Figure 1: Class Shapes
UML-style symbols (Figure 1) are used to represent classes and
connectors for “Property” and “subClassOf”. There is also a specific connector
named “Association” which can display cardinalities on ObjectProperties in a
UML like style. DataProperties and methods (verbs) are displayed within the UML
class shape. A lot of users are familiar with UML class shapes. The language
which is used and supported by the SemTalk internal inference engine is similar
to RDFS.
4. OWL-Ontologies as an
example of heavy weight ontologies
In order to be able to express the complete language set of OWL within
Visio we extended the UML shapeset with OWL specific connectors and shapes[1] (see
Figure 2).
On classes we have added the constraints “disjointWith” and
“equivalentClass”.
Different from standard SemTalk, instances are allowed in class diagrams
and are allowed to be instance of multiple classes.
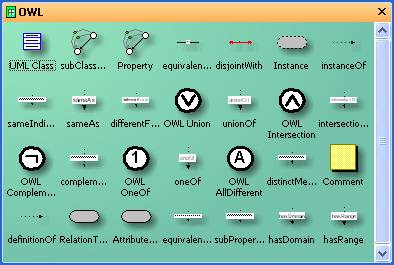
Figure 2: OWL Shapes
Anonymous classes such as unionOf
are being expressed by a mastershape (“OWL
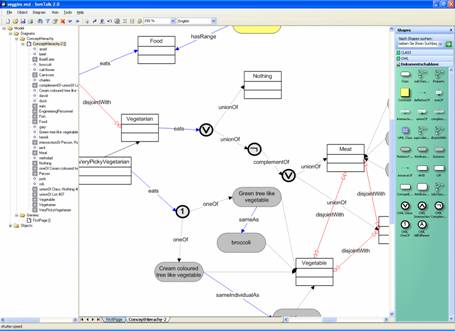
Figure 3: Anon Classes
As an addition to standard SemTalk class diagrams we have special Visio
shapes to represent ObjectProperties (“RelationType”) and DataProperties
(“AttributeType”) as objects in the diagram which can have graphical links
“hasDomain” and “hasRange” to other objects (Figure 4).
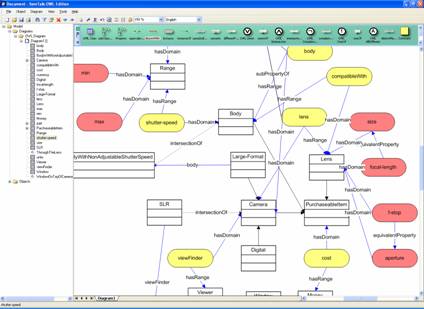
Figure 4: Properties in an OWL Diagram
Using these expressions new OWL files can be created and existing OWL
files can be presented in a manually or automatically arranged way.
Because predefined Visio shapes can be used to represent classes and
objects, OWL models designed with SemTalk are often better understandable for
non-technical end users than models created with other tools.
Even if the graphical notation makes authoring OWL simpler than entering
the same OWL data with other tools, it does not educate people in Description
Logic.
Compared to the amount of users entering knowledge using MS PowerPoint
and MS Visio, the number of users specifying knowledge with OWL will be small
and limited to technical experts integrating IT-Systems in EAI or Portal scenarios.
We do not expect people to annotate their documents manually by modelling the
contents of documents in a way inference engines can “understand” the
documents.
Resulting from complexity of the DL-modelling paradigm in full OWL even
for stand-alone models an inference engine is needed to prove their
correctness.
For some of the constraints it also makes sense to enforce consistency in
a distributed environment even for taxonomies. This is especially true for
disjointness, which can be violated without using any other OWL constructs other
than subclassOf.
A major challenge we see for inference engines is to support the
distributed modelling of business processes including support for finding
homonyms. Homonyms are different words having the same meaning.
5. Tools for Sem antic Web Authoring
In the early nineties business process modelling has started from
revolutionary ideas of Michael Hammer, who proposed business process
reengineering. Pushed by the success story of ERP systems, 10 years later process
modelling made its way from an academic discipline using research prototypes to
a commercial component integrated in Microsoft Office used for any serious
system integration.
Ontology modelling is still in its early stage. Most ontologies are made
by academics using non-commercial tools which have their roots in research
often in Artificial Intelligence. The “Semantic Web” in its original sense seems
to be far away from reaching the critical mass required for a takeoff. But
semantic technology is one of the very few technologies of the last decade
which seems to ignore Gartner’s “Hype Cycle” [Eric Miller, STC05]. There has
been slow but continuous growth on semantic technology and an end is not
foreseeable.
Ontologies offer great value to common modelling problems especially to
process modelling. Specification of procedural knowledge in processes is very
common. Specification of static knowledge and rules in ontologies can be seen
as an extension. Support for maintenance of static and dynamic knowledge will
become part of knowledge worker’s workplace. Building end user tools for static
knowledge can and will benefit from experiences made with process modelling
tools.
5. Conclusion
We believe in ontology modelling as a great way of enhancing current
possibilities of writing computer programs on one hand and of closing the gap
between users and IT specialists on the other hand. For this we see the need to
enable everybody to develop, document and maintain his or her ontology, be it
in a conscious manner using DL metaphors or be it unconsciously while modelling
a business
References:
[
[GRU95] Gru
[HF03] van Hoof,
[FWW02] Fillies, C., Wood-
[OWL02] OWL We