Towards the Corporate Semantic Process Web
1 Semtation GmbH, Bredower Str. 145
14612 Falkensee, Germany
2 Beratung im
Netz, Merkurstrasse 17,
14482 Potsdam, Germany
Abstract. The article gives an overview on how Business Process Modeling can be made more efficient and reusable by applying some simple ideas borrowed from the new concept of the "Semantic Web" [1] to process modeling. The main idea of the Semantic Web is to form a world wide web of formal models in addition to the existing web of text. This concept is applied to process modeling by relating ontologies [2] and process elements. By the use of ontology-based process modeling tools such as SemTalk [3], reference models will be built and used in a decentralized manner. Integration with the MS-Office Suite enables even casual users to contribute to the Corporate Semantic Process Web in a way that their knowledge will become beneficial for their company. We are demonstrating how this concept can be used by discussing some real world examples such as localization of models, reference models for E-Government and process templates for MS-Project.
1 Separation of Ontologies and Processes
Using traditional Business Process Modeling tools one can enter arbitrary names for activities and objects in a process. Especially if the business is being modeled in parallel by multiple persons, external consultants or for more than one department at a time, the result will be a redundant and inconsistent model, which is hardly maintainable. This effect is nearly independent from the multi-user capabilities of the modeling tools being used. Even a central repository does not ensure consistency of the model on its own, as long as the internal organization of the model is not coordinated. Some modeling methodologies have a strict level of hierarchies and well defined interfaces between main process components. Applying them might help in specific situations[1] . In general such a black-box strategy helps to reduce the problem space into sub problems. The major disadvantage of this approach is, that the overall model can not be analyzed as a whole anymore because of a lack of common terminology in the sub models.
The described problem becomes critical as soon as you localize such a model to foreign languages. A lot of the used nouns will be recognized as synonyms. These are multiple words with the same meaning. Even worse, but quite common cases are homonyms. These are model objects, which refer to different meanings for the same term. The solution is quite obvious as soon as you investigate existing models: The names of the activities are very often a composition of a verb and a noun such as write business plan. Virtually all used activity names can be created using this simple scheme. Such an 'object-oriented' wording cannot be realized in every interview situation, but it can be trained with users easily. Even some object-oriented reengineering of the model after the interview may be accomplished if there is some tool support for this. Beyond this there is another lesson learned from object-oriented modeling in software engineering. It is always a good idea to use as few flexions as possible. Especially singular and plural forms of a noun should not be mixed.
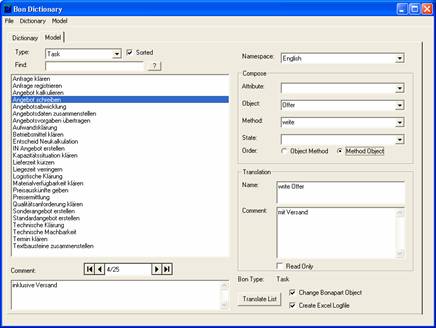
Fig. 1. Recycling tool for process models
A major German pharmaceutics company got aware of these problems with legacy models. In order to preserve the taken investments in process modeling a database was set up, which helped to systematically clean object and task names in the model (see fig. 1). This is done by creating a single dictionary (serving as a glossary for future use). The renaming of the objects in the real model is done automatically. After these steps the translation of large models to several European languages could be made with reasonable effort.
In the next chapters we are explaining our approach for ontology-based process modeling in detail. Using the approach, which mainly is focused on reusability, prevents the models from experiencing the translation problem as a side effect.
1.1 Composition of task names
Modelling tools,
which have support for an ontology-based approach such as SemTalk, explicitly
use objects and their methods to construct elements of the model and to keep
them consistent. write business plan
and review business plan are tasks
referring to the same object named business
plan. In case business plan is
going to be renamed all tasks and their occurrences on diagrams are going to be
updated. There are two ways how to build the ontology and the process.
Following the bottom-up approach classes and verbs are found while creating the
process. The top-down approach favours to create an ontology first as a library
and use it afterwards while creating the actual process.
One
important aspect is that the verbs (or "methods") are going to be
inherited from general classes to the more specialized classes. Consider a task
like review plan and the fact that a business plan is a specialization of (or
subClassOf) a plan. For the task review
business plan the class business plan
inherits the verb review from the
more general class plan.
Object-oriented specialization helps to find the right layer of abstraction of
the concepts being used.
1.2 Distribution of Models
Some activities
like write plan and review plan are obviously useful beyond
a certain department or business process, while business plan is a more specific class which will be used in fewer
processes. The knowledge what a plan is, is virtually static. It nearly never
changes. The meaning of the word business
plan and its actual components are changing a bit more often, but less
often than the processes a business plan
is involved in. The consequence of this observation is to split the models into
several smaller models. These sub models may be located physically on different
places and even may be maintained by different persons. Each of these models
contains a set of objects on a specific layer of abstraction. It may be divided
into multiple logical scenarios or contexts.
For some
projects it has been useful to invest some manual effort into the graphical
layout of those scenarios. Once the concepts have a textual definition,
synonyms and eventually graphical symbols, the model may be published for human
reference as HTML on the intranet. Even casual users are getting a chance to
understand the concepts and terminology just by looking on the contextual information.
Using namespaces multiple meanings of a word can be represented and -even more
important- explained.
During the
actual making of the process model the user has the option to select one or
more contexts and ontologies, which are relevant for his current use case. The
tool supports him while adding new terms by offering existing terms from the
ontology. It also will look up terms in the selected ontology and give access
to associated concepts, more general or more specific concepts.
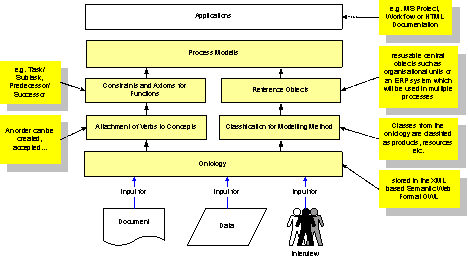 Fig.
2. Types of Models used for BPM
Fig.
2. Types of Models used for BPM
As
visualized in figure 2, documents, data models and interviews are the major
sources to build ontologies. There are class models for abstract concepts and
instance models describing specific objects. Some models will pre-classify the
concepts in respect to the applied BPM method. In that sense there are
libraries for products, types of organizational units, types of media etc. Even
concrete objects like a distinct department or a SAP system may be part of such
a library in order to be able to reuse it later on in multiple business
processes. For the purpose of business process models the classes will be
described with applicable verbs. These models are the foundation of a component
library to be used in multiple process modelling projects and applications such
as project management based on those processes.
1.3 Semantic Web
In case an object like order
is going to be used from an external library in a local model, a copy (proxy, stub..) of
that concept will be created. This local object keeps a reference to the
external object as shown in figure 3. By using this reference, objects can be
replicated similar to the functionality known from Lotus Notes databases. They
are being updated on demand in case the referenced objects have been modified.
Users may browse the external library in order to extend their local model by
related objects from the external model. Objects have a unique name (URN) and a
physical address or location which specifies how to retrieve their
specification. This may be a file or a server which actually stores the master
definition.
The
architecture is strongly related to a concept known as "Semantic
Web", proposed by the W3C. The main idea is to create a kind of internet
made of data additional to the existing web made of text. This is the main
reason why we are using the W3C notation OWL [4] for representing model data.
There is an alternative format named ISO Topic Maps which has its primary focus
in describing meta information for documents. Semantic Web has its focus in
models as elements of knowledge, rather than modelling documents.
We are
extending the approach of the Semantic Web, which is mainly about static
information models, by process components and workflow descriptions as new elements
of knowledge. Related work to our approach has been undertaken in the DAML-S
community [5]. They are describing web-services using process models. Both
approaches add procedural knowledge to static knowledge. In case of DAML-S the
static knowledge is the input / output specification coming from WSDL [6].
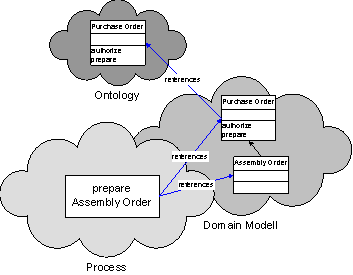
Fig. 3. Types of Models used for BPM
To
partition models into independent linked sub-models without having a central
coordinating consistency checker is very similar to hyperlinks in HMTL. It
makes it easy to reuse knowledge, but has built in the risk of broken links.
There is some significant manual effort in maintaining the evolution of an
ontology. The major task is to decide which concepts are included in a specific
model having a definition agreed by the community. This effort has to be
undertaken regardless which modelling tool or strategy is being used. There
seems to be no way how this ever will be done by machines.
The main
advantage of the proposed method is to make offers to those people building
their personal models. We are offering to use objects which are consistent with
the corporate terminology, but we do not strictly enforce this consistency.
This is reducing modelling efforts because people can reuse existing
components. It also tries to avoid time consuming approval processes, which
very often are the reason for not using central glossaries.
1.4 Creating Ontologies
The ontology
usually covers central relevant terms with their definitions and relations to
other terms. Sources for those terms are text, interviews and workshops. There
are a couple of tools available to support the development of the ontology.
Some of them are databases linked to document management systems. Others are
text-mining tools, which help to extract domain specific terms. The ontologies
are stored using the Semantic Web format OWL. They are available as a library
for use in modelling projects. Especially for the use in process models, verbs
and attributes may be included in the ontology.
Fig. 4. Subset of a German
E-Government Ontology
Very often
external glossaries are used in this situation. A very popular repository to
use are business objects from SAP's ASAP toolkit. There are a couple of other
ontologies available on the web, some of them even in the Semantic Web format
OWL or its predecessor DAML+OIL [7],[8],[9].
1.5 Task Structure Models Composition of task names
Once having
created ontologies and assigned relevant verbs these will be used to define
libraries of activities. These libraries contain information about tasks and
possible subtasks. Tasks are basically independent from the concrete sequence
in a process and describe the list of potential subtasks of a process. They
establish the repository of tasks needed to build a concrete process together
with the domain expert. The task
structure shown in figure 5 gives an impression how such a task structure might
look like.
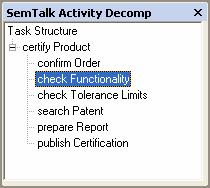
Fig. 5. Task / Subtask
structure
If you look
at certify product you will notice
that check Functionality might be an
important process step. In this model there is nothing stated about this
subtask being optional or mission critical for the process. There will not be
any ordering of the subtasks at all in this library. It is just a list of
possible components. Further consistency rules can be specified. You might say
that a certain task must be a predecessor of another task. E.g. an order must be confirmed before it is
being processed. These rules will enforce a sequence of task in the processes.
1.6 Consistency Checking
SemTalk can
validate those rules locally for one model and the set of processes included in
the current model. Because the models are saved in a W3C compliant format, the
rules (or "axioms") can be checked for multiple models by Semantic
Web inference engines such as Cerebra from Network Inference or Ontobroker from
Ontoprise GmbH. This technology is used to find non trivial inconsistencies in
multiple models.
Let´s
assume we have two business processes modelled. One of them describes the order entry and the other one order processing. Let´s further assume
that there is a consistency rule stating that only confirmed orders can be
processed. Both processes may have been made independently of each other by
their respective process manager, but refer to the global object order. The problem is, that the order
processing department usually begins working on a prototype after they made a
bid. Even if there are no local consistency problems in both of the models,
there is a conflict in the union of both models. This is a typical BPM problem
that can be detected using Semantic Web inference engines.
Ontology-based
process modelling solves some of the most important problems which could be
identified analyzing business process models from past projects:
-
Modularization
of models
-
Improved
maintainability
-
Less
learning effort for casual end users
-
Sharing
terminology with other knowledge intensive technology
-
Use
of reference objects instead of reducing large monolithic models
Ontology-based
process modelling is not the silver bullet in every modelling situation. The
examples mentioned in this paper such as localization of plant building and
plant maintenance in the pharmaceutical industry or E-Government reference
models obviously have a strong character of reference models (see chapter 3). A
consulting product like E-Government Quick-Check[2] can be offered with a better quality and for a
better price once there is enough pre-defined content available. Even with
respect to all local specialities, processes of the local authorities are strongly
bound to legislation. The same applies to chemical industry.
The process
modelling community is divided into two major groups. There are IT-departments
and consultancy firms which are using standard BPM tools. These users usually
made a fairly high investment in tools and process modelling education. The
other group are the actual owners of the processes coming from various
departments. They are mainly using MS PowerPoint or Visio. This group does
usually not focus on reusability and company wide consistency. Quite often MS
Project is used directly in order to specify a planned task. The problem which
arises is that all the knowledge formalized by the second group is more or less
lost from the company's or IT departments point of view. Given this problem we
are supporting the IT department in offering a solution which covers both
interests: company wide consistency and reusability in the "Corporate
Semantic Process Web" and the use of
MS-Office presentation tools for fast result.
2 Process Modeling Methods
Visio is a
popular drawing and flow charting tool. SemTalk extends Visio by the functionality
which is needed for business process modelling. It provides support for navigation,
consistency and reporting. It bridges the gap between professional BPM experts
and casual users, because it is offering support for standard BPM methods
within Visio. Modelling methods can be defined graphically within Visio using
SemTalk (left side of figure 6). The semantics of a Visio shape is being
defined in this meta model. The meta model defines which types of shapes can be
connected with other shapes, on which diagram types they appear, which
attributes they have etc. This open architecture allows to define new modelling
methods in a fast and flexible way.
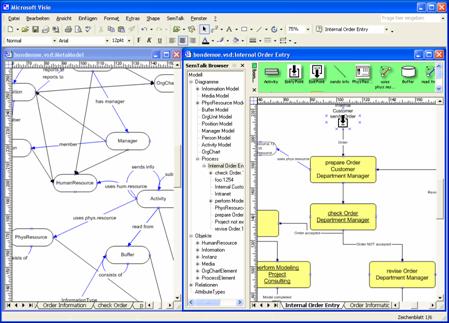
Fig. 6. MetaModel of a BPM
Method
SemTalk
comes with a set of predefined BPM methods such as SAP's Event Process Chain
(EPC), IMG AG's Promet [10] and the Communication Structure Analysis (CSA)
known from Bonapart [11]. Each of these methods can be logically and graphically
customized to match the requirements of customers.
Certain
problems require a specific view on a business process in order to visualize a
certain aspect of the model. The E-Government models have been described using
the CSA notation which emphasises the flow of information in a process rather
than the flow of control. In order to visualize specific questions relevant for
E-Government such as the responsibility of organisational units or the change
of IT-systems, a swim-lane notation for each view on the process may be
generated (Figure 7). These visualisations are well suited to discuss the
problem together with the involved users. This is a good example how we can use
the graphical options of Visio in conjunction with the flexible meta model
concept of SemTalk.
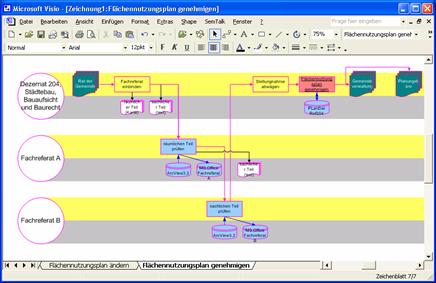
Fig. 7. Swim-Lane View of
a Process
Beyond the
open meta model, the main difference to other modelling tools is the ontology
based modelling method which can be applied to any chosen BPM method.
3 Use Case: Project Management
Mission critical goals are being reached in
global organizations using a project based structure and project management tools. A similar range of
problems as discussed in the paper also applies to project plans, if they were
made using traditional project management tools.
The
proposed solution is to generate project plans from modelled business processes.
It is assumed that those plans will increase the reliability and accuracy of project
execution. It will lower the risk to redo process steps which have been
recognized as being misleading (minimization of risk). It ensures that those
project steps which have proven to be successful will not be omitted (quality
assurance). The overall efficiency will be improved by learning from reference
projects.
In order to
validate this process based approach the pharmaceutical corporation made an
internal study to find out how far it will improve project management. The
study basically followed the criteria worked out in a recent study of FHG-IAO
[11]. Several project managers have been interviewed and a couple of business
process modelling tools have been evaluated. The overall result of the
evaluation of the interviews was, that using a template based approach will be
helpful in order to gain more control and comparability over the project
execution schedule. A second result of the investigation was, that there is a
major demand in integration capabilities of the tools used.
Looking
closer, it became clear, that tools are needed that would be able to store and
present complex process structures as reference models. Based on these
reference models project plans are generated; project mangers have to be able
to customize these reference processes. Therefore the tool has to support
distributed modelling. Furthermore there has to be an interface between the
modelling tool and the project management tool. The tool has to be flexible
enough to customize models or plans in a defined way to assure fulfilment of
basic requirements.

Fig. 8. Value Chain
“Project Plan”
Object
oriented modelling of process elements enables people to develop and maintain
complex models of high quality with relatively small effort. A reference model
based system can be realized in a rather easy way by using distributed
modelling and ontology based modelling mechanisms.
To
establish the interface between process modelling and project management a tool has been developed
to map processes in the process library and plans in MS Project.
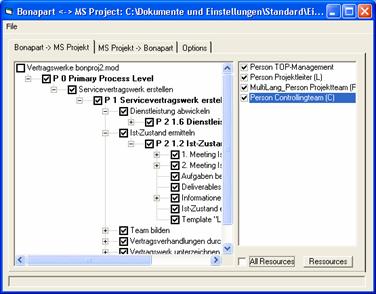
Fig. 9. MS Project
Interface
Representation
of processes that were to be used as MS Project templates was done with the CSA
method (Bonapart). This method matches the meta model of MS Project fairly
well, as it has clearly defined semantics based on coloured Petri nets that fit
with modelling elements of MS Project
Furthermore
this method is a good choice
·
if
models are to represent the working together of human beings or human beings
and machines,
·
if processes are complex and very hierarchical,
·
if
models are to be used on a long term and therefore need more maintenance than
others.
MS Project
is an example that clearly shows the advantages of an ontology based approach:
On one hand maintainability and transparency of processes grow significantly by
using a BPM Tool. End users acceptance rises and projects can be installed more
quickly. On the other hand using ontologies makes projects comparable concerning
the subject. Project templates can be combined in a sensible way, as subjects
of projects now are based on a commonly defined semantic system. Reuse of project
knowledge and project experiences is possible now. Going a step further and using new features
of MS Project´s latest version, integrating MS Sharepoint Portal Server will
offer a real project knowledge management system. It will be most efficient using
the same semantic system for document classification and process definition.
4 Summary and Future Research
The
proposed methodology is based on two key ideas: Composition of task names from
classes and verbs and specification of those objects explicitly in reference
libraries using the Semantic Web format OWL. This can only be done by
establishing an organizational infrastructure to maintain logical separated
reference models and a tool which supports replication of models as well as it
supports the user while selecting model elements from relevant libraries. This
approach has its strength where ever reference models are applicable. The great
advantage for the end user who really needs to create process models or project
plans as reliable, as fast and as impressive as possible, is, that he still can
use MS Visio and nevertheless be consistent with the corporate terminology.
Vice versa models created by any department can be integrated meaningfully in
the corporate knowledge management system.
The methodology
presented in this paper is independent from the notation of business processes
being used, but the notation has a significant impact on how these processes
can be interpreted by humans and machines. Semantic Web is about machine
understandable models as there are information models and process models such
as the description of web services. Some of them will be just programs. Others
may trigger complex business processes with human involvement. One of the major
goals of business process modelling has always been process optimization by
simulation. This will include in the future services, published as web
services. Process simulation is usually realized by a Petri-Net interpreter.
The behaviour of physical and human resources executing tasks is simulated in
most systems using simple queuing. Next generation business process simulation,
based on the reasoning capabilities of Semantic Web, will implement this in
much smarter way by using technologies known from agent systems that understand
the information, which is passed on a token.
"The software industry is building an
alphabet but hasn't yet invented a common language" Hasso.Plattner SAP AG, 2002 [13]. Using ontologies and W3C recommendations for
business process models is a new approach that will lead to open and distributed
reference models. Business processes can be easier combined once there is a
common semantics for the objects being exchanged. Consistency will be ensured
statically using inference engines and dynamically via simulation.
References
1. Berners-Lee, T. Hendler, J., and Lassila, O.: published an article about the Semantic Web in Scientific American. "A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities", See http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
2. Gruber, T. (1995). Towards principles for the
design of ontologies used for knowledge sharing. International Journal of Human-Computer Studies, (43):907–928.
3. Fillies,
C., Wood-Albrecht, G., Weichhardt, F.: A Pragmatic Application of the Semantic
Web Using SemTalk, WWW2002,
4. OWL Web Ontology Language 1.0 Reference: W3C Working Draft 29 July 2002, 12 November 2002. Mike Dean, Dan Connolly, Frank van Harmelen, James Hendler, Ian Horrocks, Deborah L. McGuinness, Peter F. Patel-Schneider, and Lynn Andrea Stein eds. Latest version is available at http://www.w3.org/TR/owl-ref/
5. David Martin et. al.: DAML-S 0.7 Draft Release, http://www.daml.org/services/daml-s/0.7/
6. Web Services Description Language (WSDL) 1.1 W3C Note 15 March 2001: Erik Christensen, Microsoft, Francisco Curbera, IBM Research, Greg Meredith, Microsoft, Sanjiva Weerawarana, IBM Research http://www.w3.org/TR/wsdl
7. Darpa Agent Markup Language (DAML): cf. http://www.daml.org
8. Brickley, D.: RDF(S) web service for WordNet 1.6, cf. http://xmlns.com/2001/08/wordnet/
9. A System for integrating Web Services into a Global Knowledge Base, R.V.Guha & Rob McCool http://tap.stanford.edu/ss/ bzw. http://www.alpiri.com/sw002.html
10. Information
Management Gesellschaft, PROMET 1994; Österle, Business Engineering 1 1995;
Österle/Vogler, Praxis des Workflow-Managements 1996)
11. Krallmann,
Herrmann; Feiten, L.; Hoyer, R.; Kölzer, G.: Die Kommunikationsstrukturanalyse
(KSA) - Zur Konzeption einer betrieblichen Kommunikationsarchitektur, in:
Kurbel, K.; Mertens, P.; Scheer, A.W. (Eds.): Interaktive
betriebswirtschaftliche Informations- und Kommunikationssysteme, Walter de
Gruyter,
12. Bullinger, H.-J.; Schreiner, P.: Business
Process Management Tools; Stuttgart 2001