Einsatzmöglichkeiten des Semantic Web zur Integration
von Data Warehouse und Wissensmanagement (am Beispiel von SemTalk®)
Autoren: Christian Fillies,
Dr.-Ing. Frauke Weichhardt
Stichworte: Verteilte Modellierung, Semantic
Web, Data Warehouse
1
Einleitung
Das Semantic Web [1] wird vom W3C, der zentralen herstellerübergreifenden
Institution zur Festlegung von Internet-Protokollen,
propagiert, um Informationen nicht mehr nur textuell
sondern als „Modell“ formalisiert darzustellen. Es handelt sich dabei um eine
neue Ebene des Internets analog zu HTML und XML. Dargestellt wird dabei eine neue Methode um Daten und Metadaten anwendungsunabhängig
verteilt zu repräsentieren und für verschiedenartige Anwendungen verfügbar zu
machen.[4],[5]
Dieses Semantic
Web kann aus Sicht des Endanwenders als eine Art Internet
aus miteinander durch Hyperlinks verbundenen Begriffsdefinitionen verstanden
werden, die den verwendeten Worten eine feste Bedeutung geben.
Es entstehen
damit Wissensmodelle innerhalb eines Unternehmens aber auch unternehmensübergreifend.
Obwohl das Semantic Web primär erdacht wurde, um den Inhalt von
Dokumenten darzustellen, ist es sinnvoll, denselben Ansatz auch auf andere
Bereiche anzuwenden, in denen eine gemeinsame Sprache und wohl definierte
Begriffe benötigt werden. Dies trifft beispielsweise auf die Inhalte eines Data
Warehouse zu. Im Folgenden wird ein Projekt aus einer deutschen Krankenkasse,
der AOK Berlin, vorgestellt, in dem dieses Konzept auf die Einführung und den
Betrieb eines Data Warehouse angewendet wurde.
2
Semantisches Web
und Data Warehouse
Im Data
Warehouse werden Definitionen für Kennzahlen und Kontexte,
in denen diese Kennzahlen verwendet werden sollen (Dimensionen), einheitlich
bestimmt. Um sie zu verwenden, werden Würfel und Berichte definiert, in denen
Kennzahlen und Dimensionen kombiniert werden. Die Dokumentation dieser Metadaten
eines Data Warehouse ist von großer Wichtigkeit, da die Anwender wissen müssen,
auf welcher Basis ihre Auswertungen durchgeführt werden; das heißt also, daß
die Definitionen der Elemente nicht nur für die Entwickler sondern auch für die
Anwender zur Verfügung stehen müssen. Die Dokumentation der Metadaten läßt sich
als Wissensmodell in Form einer Ontologie [3] interpretieren. Sie muß in einer
Form durchgeführt werden, die es einerseits dem Entwickler auf einfache und
effektive Weise ermöglicht, die von ihm entwickelten Inhalte darzustellen,, und
andererseits dem Anwender eine einfache und gezielte Form des Zugriffs auf die gewünschten
Inhalte zur Verfügung stellt.
Eine grafische Notation der Ontologie
mit Hilfe eines Modellierungstools bietet sich hier an, da damit eine
effiziente Verwaltung der Metadaten-Dokumentation mit einer einfachen
Darstellungsweise kombiniert werden kann. Um die Dokumentation durch
verschiedene Entwickler in den einzelnen Fachabteilungen zu ermöglichen, muß
die Modellierung unabhängig von einander erfolgen können. Zur Unterstützung
dieser Funktionalität bietet sich die Nutzung von Technologien des Semantic Web an, da diese es ermöglichen, die
abgebildeten Strukturen lokal zu verwalten und sie trotzdem weiterhin zentral
koordinieren zu können. Eingesetzt wurde hier das Werkzeug SemTalk® [2] der
Firma Semtation GmbH auf Basis von Microsoft Visio.
Es ermöglicht eine Definition der jeweils benötigten Elemente und Attribute des Modells sowie der verwendeten grafischen
Elemente.
Kennzahlen
und Dimensionen werden in ihren jeweiligen Zusammenhängen mit ihren Attributen modelliert (siehe Abbildung 1). Das verwendete
Werkzeug ermöglicht dabei auch eine mehrfache Darstellung desselben Objekts in
verschiedenen Kontexten, um ein einfaches
assoziatives Suchen zu unterstützen. Auf Basis der definierten Kennzahlen und
Dimensionen können Würfel und Berichte dokumentiert werden, indem ihre Inhalte
aus diesen Elementen zusammengefügt werden. Dem werden die sonstigen
Informationen aus den Würfel- bzw. den Berichtsdokumentationen als Attribute hinzugefügt, z. B. Aktualisierungszeitpunkte,
Zuständigkeiten für Aktualisierung oder Ansprechpartner für Datenqualität. Der
Zugriff für den Anwender wird über eine HTML-Version
des Modells realisiert, das im Intranet bereitgestellt werden kann.
Konflikte in
der Benennung werden über ein Namensraumkonzept gelöst. Eine solche Definition
wird beispielsweise in einem zentralen Modell abgelegt und kann dann eindeutig
per URI referenziert werden, wie z.B.http://www.aok.de/KHB#Krankenhausbehandlungsfälle.
In dem unten
dargestellten Beispiel werden zwei verschiedene Kennzahlen in zwei
verschiedenen Bereichen mit demselben Namen "Krankenhausbehandlungsfälle"
verwendet:
- die Anzahl der Fälle für das
Fallmanagement und andererseits
- die Anzahl der Fälle für die
Verhandlungen mit dem Krankenhaus
Für die Verhandlungen mit dem
Krankenhaus ist die Berechnung
fachabteilungsbezogener Daten gesetzlich geregelt. Vergleichsdaten der AOK
Berlin müssen nach den gleichen Methoden
ermittelt werden. Interne Verlegungen werden in den Berechnungen entsprechend
dem Gesetz berücksichtigt.
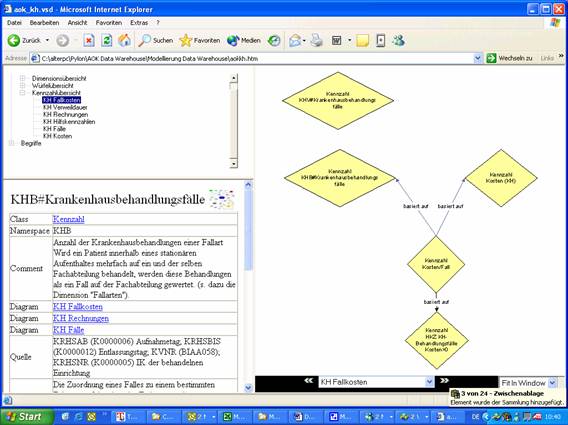
Abbildung 1: Beispiel für die
Darstellung des Datenkatalogs im Intranet auf Basis des SemTalk-Modells
Bei der
Berechnung fachabteilungsbezogener Daten des Krankenhauses für das Fallmanagement werden interneVerlegungen nur fachabteilungsübergreifend
berücksichtigt, da im Fallmanagement der Fall ganzheitlich betrachtet werden
muß. Nur so lassen sich Ansatzpunkte für das Fallmanagemant ableiten, da bei
Betrachtung nur aus der gesetzlich definierten Sicht die durchschnittliche
Verweildauer und die durchschnittlichen Kosten je Fachabteilung geschönt
werden.
Für das Data
Warehouse mußten also zwei verschiedene Kennzahlen
mit demselben Namen definiert werden. Über das Namensraumkonzept kann der
auftretende Konflikt gelöst werden. Wie bei allen Semantic
Web-Anwendungen wird auf diese Weise sichergestellt, dass alle
Beteiligten durch die Benutzung einer solchen URI über dieselbe Sache reden und
dass sich Applikationen auf dieselbe Interpretation der Legacydaten beziehen.
3
Verteilung von
Modellen
Das Semantic
Web gibt uns die Möglichkeit, auf ein zentrales Repository zu
verzichten. Dies ist sinnvoll, denn ein Repository-basierter Ansatz geht davon
aus, dass alle Beteiligten ihr Wissen in einer konsistenten zentralen Struktur
ablegen. Dieses mag zwar beispielsweise für Softwarekomponenten sinnvoll sein,
ist aber schon für mittelgroße Unternehmen für Informations- oder
Wissensmodelle schlichtweg nicht praktikabel und hemmt entscheidend den
einzelnen Mitarbeiter, zum gemeinsamen Modell beizutragen. Die Vorstellung
eines zentralen Content Management Systems für
das Internet beispielsweise, das zudem auch
noch sicherstellen würde, dass nur „wahre“ Aussagen auf den HTML-Seiten
stehen, ist sicherlich nicht realistisch. Unter diesen Umständen hätte sich das
Internet mit Sicherheit nicht in seiner
gegenwärtigen Vielfalt und seinem enormen Umfang entwickelt.
Ganz praktisch führt ein
solcher zentralistischer Ansatz dazu, dass ein großer Teil der Begriffe im
Freigabeprozess stecken bleibt und das Gesamtsystem vom Anwender abgelehnt
wird.
Aus diesem Grund wird hier
ein dezentraler Ansatz realisiert, der zentral koordiniert wird. Dabei
erstellen die Entwickler lokale Modelle ihrer Metadaten unter Verwendung
zentral definierter Begriffe.
4
Zusammenfassung und Ausblick
Wir berichten hier über
Erfahrungen mit der dezentralen Erstellung von Ontologien als
Metadaten-Dokumentation durch den Fachanwender. Die von diesen erstellen
Ontologien enthalten damit viel fachspezifisches Wissen, das nicht nur dazu
genutzt werden kann, es anderen mitzuteilen. Es ist auch möglich, dieses Wissen
in andere technische Systeme einzuspeisen.
Mit Hilfe von Semantic Web Standards sichern wir dabei die Konsistenz
in der Verwendung gemeinsamer Begriffe. Die Dezentralität des Ansatzes gibt den
Fachanwendern die Möglichkeit, eigenes Wissen einfach in ein Netzwerk des
Wissens einbringen zu können. Die Verwendung von
Semantic Web-Standards zur Wissensmodellierung
bietet dem Unternehmen dabei die Möglichkeit, das dokumentierte Domain-Wissen
von einzelnen Software-Applikationen (wie einem konkreten Data
Warehouse-System) zu separieren. Damit
wird die Grundlage geschaffen, das Wissen in anderen Applikationen
weiterverwenden zu können.
Das Semantic
Web wird die Architektur von Data Warehouse Anwendungen
grundlegend verändern. Es werden zum einen
zunehmend Informationen aus Online-Systemen ohne eine spezifische Datenaufbereitung
einbezogen. Andererseits wird es eine Mischung aus unternehmensinternen und unternehmensfremden
Datenquellen aus dem Internet geben [6]. Durch das Semantic Web
stehen Meta-Informationen über diese Daten und die Web Services, die sie
bereitstellen, abgestimmt auf konkrete Geschäftsprozesse zur Verfügung [7].
Unser Ansatz zeigt, wie sie für den Endbenutzer aufbereitet werden können,
damit er leichter verstehen kann, welche externen Daten er mit in sein
persönliches Informations- und ggf. Wissenssystem integrieren kann.
5
Literatur
|
[1]
|
Berners-Lee,T, Hendler,J. and Lassila, O. A new form of Web content that is meaningful to computers will
unleash a revolution of new possibilities Scientifc American (May 2001)
|
|
[2]
|
Fillies, C.,
Wood-Albrecht, G., Weichhardt, F.: A Pragmatic Application of the Semantic Web Using SemTalk,
WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA ACM 1-5811-449-5/02/0005
|
|
[3]
|
Gruber, T.
(1995). Towards principles for the design of ontologies used for knowledge
sharing. International Journal of Human-Computer
Studies, (43):907–928.
|
|
[4]
|
W3C. RDF
Schema Specification. http://www.w3.org/TR/PR-rdf-schema/,
1999.
|
|
[5]
|
O. Lassila and R. Swick. Resource
description framework (RDF). model and syntax specification. Technical report, W3C,
1999. W3C Recommendation. http://www.w3.org/TR/REC-rdf-syntax.
|
|
[6]
|
From Data Warehouse to Information Integration, Dr.
Barry Devlin, Procedings of DW2002 Friedrichhafen
|
|
[7]
|
A System for integrating Web Services into a Global
Knowledge Base, R.V.Guha & Rob McCool http://tap.stanford.edu/ss/
bzw. http://www.alpiri.com/sw002.html
|