Pragmatische Anwendungen
des
Christian
Fillies
SC4 Solution
Clustering
Bredower
Str 145
14612
Falkensee
André Schulze
Fachhochschule Brandenburg
Magdeburger Str. 50
14770 Brandenburg an der Havel
schulzan@fh-brandenburg.de
Dr.-Ing Frauke Weichhardt
beratung im netz
Merkurstr. 17
14482 Potsdam
Prof. Dr. Dietmar Wikarski
Fachhochschule Brandenburg
Magdeburger Str. 50
14770 Brandenburg an der Havel
Pragmatische Anwendungen des Semantic Web mit SemTalk
Zusammenfassung
Das „Semantic Web“ ist eine neue Schicht des Internet, die eine
verteilte Modellierung von Inhalten der bestehenden Webseiten ermöglicht.
Dabei werden nicht mehr nur Texte,
sondern auch Whiteboard-Files oder Skizzen mit den wichtigsten Zusammenhängen
abgelegt. Bei Verwendung normierter Ontologien entstehen so ganz neue
Suchmöglichkeiten. „Ambiente“ intelligente Anwendungen und Agenten können
dieses Wissensnetz auf vielfältige Weise nutzen.
Mit SemTalk steht ein
einfach zu bedienender Editor für Semantic-Web-Ontologien und Prozesse auf
Basis von MS-Visio
zur Verfügung. Durch ein offenes, graphisch konfigurierbares Meta-Modell kann Visio leicht an
verschiedene Modellwelten wie ARIS EPKs oder Bonapart-Modelle
angepaßt werden. Die Modelle stehen mit Hilfe von MS-Office XP
SmartTags jedem Nutzer bei der täglichen Arbeit mit Winword, Excel oder
Outlook im direkten Zugriff zur Verfügung.
Im vorliegenden Beitrag werden zwei Anwendungen dieser Technologie
vorstellt:
- Abteilungsübergreifende
Informationsmodellung bei der Credit Suisse: Die Schwerpunkte lagen sowohl
auf der sprachlichen Normierung als auch darin, eine zentrale Version
durch die bereichsspezifische dezentrale Lösungen anzureichern. Bei den
lokalen Wissensmanagern konnte ein Bewusstsein für die bereits vorhandenen
Begriffe und Lösungen geschaffen werden.
- Verteilte
Prozessmodellierung bei der Bausparkasse Deutscher Ring:
Mit mehreren Gruppen von Studenten der FH Brandenburg wurde gezeigt, wie durch die Nutzung eines branchenspezifischen
1 Einführung
Das „Next Generation Internet“ bzw. „Semantic Web“, ist ein neuer Internet-Layer, der eine verteilte Modellierung von Inhalten bestehender Webseiten ermöglicht. Dabei werden nicht mehr nur Texte, sondern analog zu Whiteboard-Images oder Skizzen, Modelle mit den wichtigsten Zusammenhängen abgelegt. Auf diese Weise entstehen bei Verwendung normierter Ontologien durch die formalisierte Darstellung der Inhalte ganz neue Suchmöglichkeiten. Ambiente („unmerklich in ihre Umgebung eingebettete“) intelligente Anwendungen und Agenten können dieses Wissensnetz auf vielfältige Weise nutzen.
Das Semantic Web
befindet sich derzeit noch im Anfangsstadium. Von vielen Seiten werden große
Möglichkeiten in seinem weiteren Aufbau gesehen, konkrete Anwendungen sind
jedoch derzeit noch sehr selten. Die Definition von XML-Protokollen wie RDF, RDFS und DAML+OIL durch
das W3C lassen eine größere Verbreitung erwarten, so dass in Zukunft mit einer
zunehmenden Anzahl von Anwendungen im
Diese neue Technologie wird sich unserer Erfahrung nach zunächst
innerhalb der Intranets größerer, verteilter Unternehmen ausbreiten, da hier
ein großer Bedarf zur Abstimmung der Strukturen von Knowledge
Management-Systemen zwischen den verschiedenen Unternehmensteilen besteht,
welcher durch die Technologien des
Mit
Im Folgenden werden zwei praktische Anwendungen der Semantic Web Technologie in Real-Life-Projekten vorstellt: Zielstellung des ersten Projekts war eine abteilungsübergreifende Informationsmodellierung bei der Credit Suisse, wobei sowohl eine sprachliche Normierung erreicht als auch eine zentrale Version durch bereichsspezifische dezentrale Lösungen angereichert werden sollte.
In dem zweiten Projekt ging es um eine verteilte
Prozessmodellierung bei der Bausparkasse des Deutschen Rings. Hier wurde mit
mehreren Arbeitsgruppen aus Studenten der FH Brandenburg gezeigt, wie sich
durch die Nutzung eines branchenspezifischen
2 Abteilungsübergreifende Informationsmodellierung bei der Credit Suisse
Im Rahmen dieses Projekts wurde in mehreren Workshops die Grundlage für ein wachsendes visuelles Glossar als mögliche Basis eines Wissensmanagement-Systems gelegt. Die Workshopergebnisse wurden abei in Form von Konzeptmodellen zusammengefasst und im Intranet zur Verfügung gestellt.
2.1 Ausgangssituation
In heutigen Großunternehmen herrscht durch den schnellen
technologischen Wandel einerseits, andererseits durch die nach
Zusammenschlüssen mit anderen Unternehmen entstehende Situationen eine große
Sprachvielfalt vor. Besonders deutlich wird dieses im IT-Bereich, wo eine große
Zahl von Architekturbeschreibungen, Strategiepapieren, Technologiekonzepten
usw. vorliegt. Das darin enthaltene Wissen ist trotz der expliziten textuellen
Ausarbeitung oft sehr stark an Einzelpersonen gebunden und kann nur schwer
zusammengeführt werden. Typisch ist das häufige Auftreten von Homonymen, also
die Benutzung derselben Worte für unterschiedliche Begriffe. Andereseits finden
sich in der immer noch recht jungen Informatik aber auch viele Synonyme, bzw.
2.2 Ziele des Projekts
In dem Projekt sollte eine Infrastruktur und ein praktisch nutzbares Basisvokabular ausgearbeitet werden, mit denen bestehende Dokumente sprachlich vereinheitlicht werden können. Entstehende Glossare bzw. Modelle sollten generell in einer möglichst flexibel wieder verwendbaren Form repräsentiert werden, um sie später leicht auch in technischen Applikationen wie Document Management- und Content Management Systemen einsetzen zu können. Eine weitere Anwendung ist die automatische Dokumentenklassifikation.
Der Schwerpunkt in diesem Projekt lag auf einerseits auf der sprachlichen Normierung und andererseits darin, eine zentrale Version eines Glossars durch bereichsspezifische dezentrale Lösungen anzureichern. Es ging nicht darum, dogmatisch zentrale Vorgaben zu erlassen, sondern beim lokalen Wissensmanager oder Modellierer ein Bewusstsein für die bereits vorhandenen Begriffe und Lösungen zu schaffen („Awareness“). Um eine dauerhafte Umsetzung in die alltägliche Praxis zu gewährleisten, musste auch bei den Anwendern ein Bewusstsein über bereits vorhandene Kontexte erzeugt werden, indem in ihren täglichen Anwendungen auf die grundlegenden Begriffsdefinitionen und Modelle Bezug genommen wurde. Auch hier ging es nicht um einen Zwang zur Anwendung der definierten Begriffe, sondern um die Schaffung von Awareness, z.B. durch die Integration mit Office XP.
Es war von Projektbeginn an eine zentrale Forderung, dass das Glossar im Intranet in einer für verschiedene Benutzer geeigneten Form dargestellt werden muss. Aus dieser Anforderung lässt sich ableiten, dass keine komplizierten technischen Notationen wie z.B. UML-Diagramme genutzt werden sollten.
Generell sollte dabei ein möglicher Grundstock für das zukünftig aufzubauende Wissensmanagement-System gelegt werden. Insbesondere das "Bootstrapping" eines solchen Systems ist immer ein sehr aufwendiges Vorhaben. Ist initial zu wenig Inhalt vorhanden, wird das System wenig genutzt und fängt dann auch nicht von allein an zu leben. Versucht man hingegen eine vollständige Ontologie aller im Unternehmen existierenden Objekte zu erstellen, wird man einerseits nie fertig und läuft zum anderen Gefahr, dass die dabei entstehende "Normsprache" mit der sich schnell verändernden Welt des Anwenders wenig zu tun hat.
Deshalb ist es essentiell, zunächst eine hinreichende Basis an Inhalt bzw. Definitionen zu schaffen und dann jedem einzelnen Benutzer die Möglichkeit zu geben, sein Wissen im System zu publizieren in der Hoffnung, dass das System sich dann selbst mit Inhalt füllt. Dieses setzt natürlich leicht zu bedienende und in Office integrierte Werkzeuge voraus. Ähnlich wie beim Erstellen und Indizieren von textuellen Webseiten muss es auch hier gelingen, an das Bedürfnis zur Selbstdarstellung zu appellieren.
Innerhalb dieses Projektes wurden jedoch zunächst nur die Schaffung und Modellierung eines Glossars angestrebt.
2.3 Ein Semantic Web als Wissensmanagementsystem
Das Glossar besteht aus Begriffen mit Definitionstexten und Synonym-/
Homonym-Beziehungen. Da es daneben aber auch explizite Beziehungen zwischen den
Begriffen und Klassifikationen in Ober- und Unterbegriffe gibt, bietet sich die
formalisierte Darstellung als Modell an. Neben Topic Maps ist die W3C
Recommendation
Als graphischer Editor wird
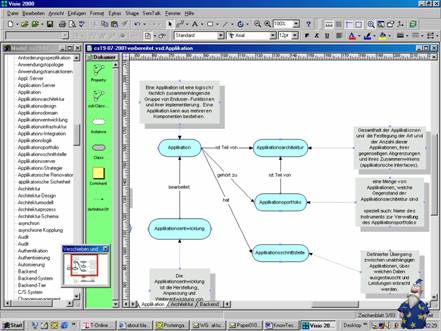
Abbildung 1:
Ausschnitt aus einem
Die Konsistenz zwischen den verschiedenen Teilmodellen wird
während der Modellierung durch den
Diese Indextabellen werden auch beim Arbeiten mit MS Office genutzt. SemTalk SmartTag ist eine Technologie, die die Texte beim Schreiben analysiert und die Worte markiert, die im Glossar als Referenzbegriff oder Synonym enthalten sind. Gefundene Synonyme können bei Bedarf mit den Referenzbegriffen ausgetauscht werden. Die Definitionen der erkannten Worte stehen mit einem "Klick" sowohl im Visio Modell als auch als HTML Darstellung zur Verfügung. Auf diese Weise kommt es zu erheblichen Einsparungen bei der aufwendigen manuellen Überarbeitung der Texte.
Mit Hilfe der
Zur Erstellung spezifischer Modelle, z.B. zur Darstellung
detaillierter Zusammenhänge aus einzelnen Dokumenten, die nicht in das
allgemeine Glossar eingehen sollen, wird
Falls bei der Überarbeitung einzelner Dokumente neue Begriffe für das allgemeine Glossar auftauchen, werden diese dann nach Abstimmung in das allgemeine Glossar eingearbeitet.
Die Initialisierung eines Wissensmanagementsystems geschieht i. A. durch Workshops, meist mit Experteninterviews. Signifikante Einsparungsmöglichkeiten ergeben sich hier durch die Möglichkeit der Terminologieextraktion mit Hilfe des Concept Composers.
- Der
Concept
Composer wird eingesetzt
zur Suche in größeren Textmengen (Quell
- als
Informationssystem "Concept
Presenter" im Intranet mit graphischer Oberfläche, ggf.
integriert in den
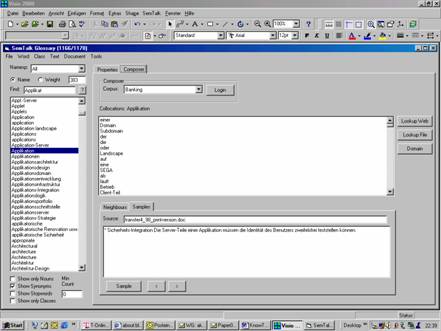
Abbildung 2: Verbindung mit dem Concept Composer
Mit dem SemTalk
Glossary Glossary können verschiedene Versionen von Definitionen verwaltet,
Synonym-/Homonym-Zuordnungen
getroffen und Textstellen gesucht werden. Das
2.4 Vorgehensweise beim Bootstrapping:
- Erstellung einer Liste zentraler, prioritär zu definierender Begriffe
- Einlesen von 100 repräsentativen Dokumenten in den
- Durchführung von drei Workshops mit 3-5 Tagen mit bis zu
fünf Experten. Während des Workshops wird zur Dokumentation und Verwaltung von
Begriffsdefinitionen das
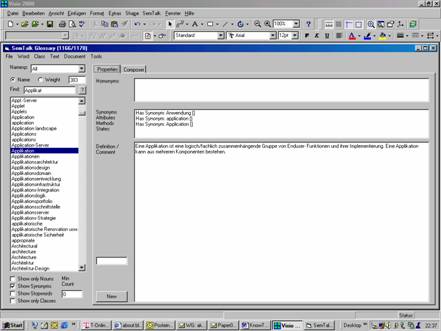
Abbildung 3:
Am Ende eines jeden Workshop-Tages werden die untersuchten
Szenarien dann graphisch in
Am Ende der Workshops sind die zentralen Begriffe definiert und graphisch modelliert. Das Glossar steht nach der Modellierung mit der Graphik im Intranet zu Verfügung.
2.5 Der Knowledge
Management-Prozess
Das Glossar wird in seiner Initialform im Intranet zur Verfügung gestellt. Ein periodisches Audit über den Inhalt gewährleistet die Aktualität und den Nutzen. Änderungsanforderungen werden dabei zentral gesammelt und in regelmäßigen Abständen zwischen den Abteilungen abgestimmt. Das Update des Modells wird auf Basis der Abstimmungsergebnisse durchgeführt. Die Verantwortung für die Durchführung dieses Prozesses liegt dabei bei den Intranet-Verantwortlichen.
2.6 Ergebnisse des Projekts
Innerhalb von sieben Tagen Workshop, verteilt auf drei Monate, wurden die 200 vordringlichen Begriffe der beteiligten Abteilungen definiert und im Anschluss in ca. zwei Tagen modelliert. An den Workshops waren rollierend ca. 10 Personen beteiligt. Der Aufwand für den einzelnen Mitarbeiter lag zwischen zwei Stunden und drei Tagen. Damit konnte in sehr kurzer Zeit der zähe Prozess der Begriffsabstimmung effizient durchgeführt werden. Die Unterstützung durch das SemTalk Glossary Glossary war dazu eine notwendige Voraussetzung.
Die Ergebnisse werden im Intranet publiziert und periodisch
aktualisiert. Die Modellierung mit SemTalk ermöglicht
einen Zugang zu einzelnen Begriffen über verschiedene Kontexte. Die grafische
Darstellung erhöht die Handhabbarkeit und das Begriffsverständnis, da bei der
Suche nach einem spezifischen Begriff der zugehörige Kon
Mit Hilfe des Projekts wurden Effizienz und Effektivität der Kommunikation zwischen den Mitarbeitern der verschiedenen Abteilungen gesteigert. Zusätzlich wurde der Grundstein gelegt für eine zielgerichtete Überarbeitung von Dokumentationen, indem deutlich wird, welche Dokumente angepasst werden müssen, wenn sich zentrale Begriffskontexte verändern.
2. 7 Ausblick
Das für Credit Suisse erstellte Glossar wird derzeit erprobt. Bei erfolgreicher Probe wird die Ausweitung der Methode auf andere Abteilungen bis hin zum gesamten Unternehmen erfolgen.
3
Verteilte Prozessmodellierung bei der Deutscher
Ring Bausparkasse
Hauptziel dieses mehrwöchigen Projekts mit Studenten der Fachhochschule Brandenburg war die Modellierung.der Antragsbearbeitung bei der Deutscher Ring Bausparkasse.
Ein wesentlicher Unterschied zu konventionellen
Prozessmodellierungsprojekten bestand dabei darin, dass durch die Nutzung eines
branchenspezifischen
3.1 Rahmenbedingungen und Ziele
Es wurden mit zwei getrennten Gruppen alle in zwei
vorgegebenen Abteilungen vorkommenden Geschäftsprozesse modelliert. Jeder
Abteilung war eine vierköpfige Studentengruppe zugeordnet, welche die Prozesse
ihrer Abteilung systemanalytisch erfasste und anschließend in
Die primären, durch den Kunden vorgegebenen Ziele waren die Schaffung von mehr Transparenz im Unternehmen sowie die Vorbereitung der Einführung eines Workflow-Management-Systems.
Ein wesentliches Projektziel bestand aber auch darin, den verteilten Modellierungsprozess selbst zu untersuchen. Es sollte herausgefunden werden, wie sich die Kommunikation innerhalb der Modellierungsteams und mit den Anwendern verbessern lässt.
Eine Erfahrung aus vielen GPO-Projekten besteht darin, dass für einequalitativ hochwertige verteilte Modellierung ein Modellierungswerkzeug mit einem gemeinsamen Repository nicht ausreichend ist. Ein solches Repository stellt im besten Falle die syntaktische Konsistenz der Modelle sicher, indem es die Prozessschnittstellen verwaltet. Es liefert aber praktisch keine Hilfe beim Kernproblem, der Schaffung einer gemeinsame Begrifflichkeit für Aufgaben, Prozesse und Informationen. Diese Problematik wird um so wichtiger, wenn unternehmensübergreifende Prozesse, z.B. im B2B Bereich, erarbeitet werden, da die verschiedenen Geschäftspartner zunächst ihre "Unternehmenssprachen" mit einander verbinden müssen.
3.2. Vorgehen bei der Prozess-Modellierung mit SemTalk
Die wichtigste Philosophie des Internets und damit auch des
Das Vorgehen bei der Prozessmodellierung mit einem
- Auswahl geeigneter Referenzbiliotheken im Internet
- Customizing dieser Bibliotheken für den Projektbedarf
- Erstellung der Prozessmodelle vor dem Hintergrund der Referenzmodell
3.2.1. Das Semantic Web liefert die Referenzmodelle
Unsere Vorgehensweise besteht im Wesentlichen darin, schon
im
- http://www.dmtf.org
develops Ontologies for the Telecommunication Industry
- http://www.bpmi.org
develops a Process Ontology for Representing Business Processes
- http://www.papinet.org develops
global transaction standards for the paper supply chain.
- http://www.hr-xml.org is dedicated to
the development and promotion of standardized XML vocabularies for human
resources (HR).
Es werden dabei zur Zeit noch verschiedene XML basierte Sprachen genutzt. Populäre Repositories aus dem EAI Bereich sind BizTalk www.biztalk.org , RosettaNet u.a.
Allgemeine Begriffssysteme auf XML Basis findet man bei www.cyc.com und mit Wordnet bei www.xmlns.com
Diese Referenzmodelle können natürlich auch die Quelltextanalyse wie im ersten Teil beschrieben erweitert werden.
3.2.2 Prozessmodellierung
In der KSA und damit auch in
In der KSA und damit auch in
„Paginiernummer zuorden“ ist die Klasse der Aktivitäten „Paginiernummer zuorden.1“ im Prozess „AdressÄnaderung“ und aller anderen Stellen wo „Paginiernummer zuorden“ auftaucht. „Paginiernummer zuordnen“ ist als Klasse z.B. Unterklasse der Klasse „Nummer zuordnen“. Auf Klassenebene wird auch beschrieben, welche möglichen Teilaufgaben bestehen.
Die Klassenmodelle helfen bei der Strukturierung und der Erhaltung der sprachlichen Konsistenz der Prozessmodelle. Sie bilden die Grundlage zur Wiederverwendung und besseren Auswertbarkeit der entstehenden Modelle.
Mit
Erst über die Objekte und dann über die Abläufe nachzudenken empfiehlt sich aber zumindest in der Anfangsphase um eine konsistente Basis zu schaffen. Wichtig ist, dass die Klassenmodelle über die verschiedenen Teilprojekte hinweg konsistent sind. Dann ist es auf einfache Weise möglich die entstandenen Teilmodelle und Prozesse wieder zu integrieren.
3.2.3 Ein Beispiel
Zum besseren Verständnis der verteilten Modellierung
mit
In unserem Beispiel findet
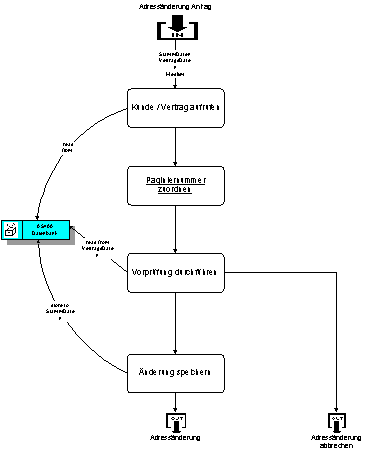
Abbildung 4:
Beispielprozess „AdressÄnderung“
3.2.4 Toolunterstützung durch SemTalk
bei der Modellierung
Zur Animation werden der Agenten wird das aus
3.4. Verallgemeinerbare Erfahrungen aus dem Projekt
Um dem Thema dieser Publikation Rechnung zu tragen,
konzentrieren wir uns hier auf die Erfahrungen bei der Modellierung mit
1. Mit
2. Als besonders wichtig hat sich die Maxime erwiesen, die Klassenmodelle über die verschiedenen Teilprojekte hinweg konsistent zu halten . So war es auf einfache Weise möglich, die entstandenen Teilmodelle und Prozesse wieder zu integrieren.